

In today’s fast-paced tech landscape, AWS Lambda has emerged as a game-changer in serverless computing. As organizations increasingly shift towards serverless architectures, mastering AWS Lambda is becoming a crucial skill for software engineers, developers, and cloud enthusiasts.
Whether you’re gearing up for a job interview or simply looking to expand your knowledge, this article is your key to success. We’ve compiled a comprehensive list of AWS Lambda interview questions that will not only test your understanding but also sharpen your expertise in this cutting-edge technology. Let’s dive in!
Basic AWS Lambda Interview Questions
Q1. What is AWS Lambda, and what are its key benefits?
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources, including server capacity, scaling, patching, etc.
The key benefits of AWS Lambda are:
- No server management – AWS handles all capacity provisioning, scaling, and patching behind the scenes
- Continuous scaling – Scales seamlessly from a few requests per day to thousands per second
- Pay per use – Only pay for compute time consumed when code is running. No charge for idle time
- Event-driven – Lambda functions can be triggered in response to various events like HTTP, S3, DynamoDB, SNS, etc
- Flexible – Lambda functions can be written in Python, Node.js, Java, and C#. Provides runtime environment
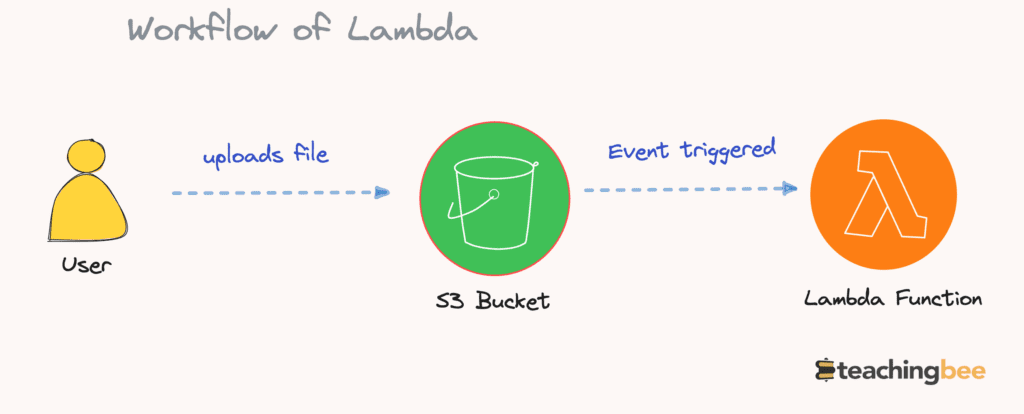
Q2. Explain the AWS Lambda architecture and workflow.
The critical components of Lambda architecture are:
- Lambda function – The code you write to process events. Packaged and deployed as container images
- Event source – The AWS service, SaaS app or custom app that generates events to trigger Lambda
- Triggers – Defines how the function will be invoked. Can be synchronous or asynchronous triggers
- Downstream resources – Other AWS resources invoked from functions such as S3, DynamoDB, etc
The workflow of Lambda is:
- Event occurs – e.g. image uploaded to S3 bucket
- Triggers associated with event sources detect an event
- Triggers invoke the Lambda function and pass event data as parameters
- Lambda provisions a container to run function code
- Function code processes events and interacts with resources via SDK
- Results returned sync or async depending on the trigger
- The lambda container is destroyed after execution completes
Q3. Explain some strategies to improve lambda function performance.
Strategies to improve Lambda function performance:
- Optimize code – use most efficient data structures and algorithms, compress payload
- Increase memory allocation – more memory = more CPU and network resources
- Keep the deployment package small – only include function code and essential dependencies
- Initialize SDK clients and database connections outside the handler function for reuse
- Use environment variables for reusable configuration instead of hard-coding
- Perform asynchronous actions instead of synchronous
- Leverage /tmp directory for temporary files to reuse across invocations
- Implement exponential backoff and retries for transient failures
- Load test function with high payload volume to identify and resolve bottlenecks
Q4. What are the different ways you can monitor and troubleshoot AWS Lambda functions?
Monitoring and troubleshooting options for AWS Lambda functions include:
- View metrics like invocations, durations, errors, and throttling in CloudWatch
- Enable CloudWatch Logs to see application logs from the Lambda function
- Use AWS X-Ray to get detailed request traces and analyze bottlenecks
- Insert log statements like console.log() within the function code
- Visualize metrics on Dashboards and configure alarms
- Check that configured triggers and event mappings are correct
- Use Lambda API to verify function configuration programmatically
- Check function logs programmatically via AWS SDK
- Use AWS CLI to inspect configurations
- Enable VPC flow logs to analyze network traffic
Q5. How do you handle dependencies in AWS Lambda functions, and where do you store them?
Dependencies like external libraries/packages used by a Lambda function can be bundled into a deployment package and uploaded along with function code.
Steps to manage and upload dependencies include:
- Install dependencies locally using a requirements.txt file for Python
- Bundle dependencies into a folder like ‘site-packages.’
- Zip the ‘site-packages’ folder together with the handler script into the deployment package
- Upload deployment package to Lambda function on creation
- Lambda will extract and make available the dependencies from the package at runtime.
Dependencies are stored on Lambda’s shared temporary storage, which has 512MB allocated by default.
Intermediate AWS Lambda Interview Questions
Q6. What are environment variables in Lambda, and how are they helpful?
Environment variables allow you to pass in key-value pairs, like database credentials or config parameters, that can be securely accessed from within your Lambda function code.
Environment variables are helpful for:
- Passing in reusable configuration, resource names, secrets, etc
- Dynamically changing config like test vs prod without updating code
- Following the twelve-factor app methodology to maintain config separately
- Reducing repetitive hardcoded values within function code
Environment variables can be encrypted using AWS KMS for added security.
Q7. What are AWS Lambda layers and how are they used?
Lambda layers allow you to pull in additional code and content to be shared across multiple Lambda functions. For example:
- Create a standard utility layer with reused libraries
- Define a custom runtime layer
Layers are added to the Lambda execution environment and process. The attached layers are unpacked and made available to function code when you invoke a function.
Layers allow better encapsulation and reuse without bloating up individual function packages. Each Lambda function can reference up to 5 layers.
Q8. How does AWS Lambda handle failures and retries during function execution?
When a Lambda function fails or errors out during execution, Lambda will retry executing the function up to two more times to see if it succeeds. This helps create robust functions to handle transient failures like network issues or temporary downstream service outages.
However, if the function fails after all three retries, Lambda discards the event and associated records if configured. The discarded events can be handled via a Dead Letter Queue or destination.
For consistent failures, you need to handle edge cases and exceptions in your code as well as monitor failure metrics closely.
Q9. What are the different AWS Lambda function triggers?
Some common Lambda function triggers are:
- API Gateway – Invoke function through HTTP request
- S3 – Trigger when files are added or changed in the bucket
- CloudWatch Events – Schedule functions using cron expressions
- DynamoDB Streams – Trigger on data change events
- SNS Notifications – Run function when SNS message is published
- CloudWatch Logs – Execute function based on log events
- Kinesis Streams – Consume and process streaming data records
- SQS – Poll messages from the queue and invoke the function
- Code Commit – Execute code after repository changes
Q10. How is AWS Lambda different from EC2 instances?
Critical differences between Lambda and EC2:
- Lambda functions are stateless, ephemeral and run on demand. EC2 runs continuously.
- Lambda auto-scales, while EC2 requires manual scaling effort.
- Lambda has no server management overhead. EC2 requires provisioning and config management.
- Lambda is event-driven. EC2 uses load balancers that poll for work.
- Lambda is cost-efficient for intermittent, unpredictable workloads. EC2 is better for steady-state, long-running apps.
- Lambda lacks OS-level access provided by EC2 instances.
Advanced AWS Lambda Interview Questions
Q11. How can you improve concurrency performance in AWS Lambda?
Strategies to improve Lambda function concurrency performance:
- Initialize SDK clients and database connections outside handler to share across concurrently executing instances
- Avoid using global variables as much as possible
- Leverage async actions instead of synchronous
- Partition event data appropriately to process in parallel
- Distribute processing by queueing batches of events from the stream
- Limit complex recursive algorithms that can slow down cold starts
- Keep the deployment package slim by only including critical code
Q12. Explain when you should use provisioned concurrency for AWS Lambda functions.
Provisioned concurrency ensures initialized Lambda function instances are ready to serve invoke events with low latency. It is useful when you have:
- Functions with consistent traffic patterns
- Critical events that require low latency invocations
- Need for fast invocations immediately after periods of inactivity
- Unpredictable traffic spikes where cold starts may increase latency
- Financial budget available for paying for allocated capacity
Provisioned concurrency is not cost-optimal for intermittent traffic and comes at an added price.
Q13. How is MongoDB Atlas typically used with AWS Lambda compared to RDS?
MongoDB Atlas provides a fully managed MongoDB-as-a-Service that easily integrates with Lambda via MongooseJS SDK. Benefits:
- Serverless, highly scalable document database
- Low operational overhead compared to self-managed MongoDB ops
- Integrated well with Lambda workflows and response times
RDS provides relational databases like Postgres MySQL that Lambda can use. However, RDS may have scaling limitations requiring capacity planning.
Q14. What are some best practices for versioning AWS Lambda functions during development?
Best practices for versioning AWS Lambda functions during development include:
- Use function aliases mapped to function versions
- Increment version for each update and thoroughly test before promoting
- Perform smoke testing on the new version before routing traffic
- Route a small % of traffic to canary test the new version
- Maintain previous versions for quick rollback if issues are found
- Monitor metrics and logs of the new version for anomalies
- Automate testing pipelines as much as possible
- Document changes for each version
- Evaluate performance impacts before replacing versions
Q15. How can you optimize AWS Lambda performance for large-scale production workloads?
At large scale AWS Lambda can be optimised by following ways:
- Streamline deployment process using CI/CD pipelines
- Automate testing thoroughly – load, integration, unit tests
- Monitor metrics for all resources used by Lambda
- Load test regularly with scale targets in mind
- Stress test-associated resources like DynamoDB
- Optimize code continuously and avoid recursive algorithms
- Use SQS to buffer event streams if needed
- Enable active tracing for advanced debugging
- Architect for horizontal scaling across AZs and regions
AWS Lambda Scenario-based Interview Questions
Q16. Design a serverless architecture to resize images uploaded to the S3 bucket.
When an image is uploaded to the S3 bucket, trigger a Lambda function via S3 event notification. This Lambda will:
- Download the image from S3 using the boto3 library
- Resize the image to the required dimensions using the Python PIL (Pillow) library
- Upload the resized image back to another S3 bucket
- Manage PIL dependency via the Lambda layer to keep the function package small
- Set S3 object tags on resized images
- Handle errors through retries and notifications
- Generate image resize metadata like dimensions timestamps and store them in the DynamoDB table
This provides an automated image resizing workflow without managing any servers.
Q17. Design real-time stream processing architecture for analyzing customer clickstream data.
Ingest clickstream data events via Kinesis Data Streams with multiple shards for high throughput. Trigger Lambda functions asynchronously to process each shard in parallel.
Lambda functions will consume batch records from shards and perform real-time analysis:
- Parse event data using JSON parser
- Enrich events with customer info from the DynamoDB table
- Calculate session metrics like duration, pages visited
- Store aggregated metrics in DDB tables
- Raise alerts for unusual activity patterns
Data can be visualized on quicksight dashboards. Use Lambda destinations for failed records.
Q18. Design video transcoding architecture for converting uploaded videos to multiple formats.
When a video is uploaded to S3, trigger a Lambda function using an S3 event. This Lambda will:
- Use Elastic Container Service to run FFmpeg docker containers
- Leverage Lambda and ECS integration to spawn FFmpeg containers
- Trigger multiple containers to transcode video files in parallel
- Convert video to required output formats like MP4, HLS, etc.
- Persist output videos back to S3 when encoding completes
- Use SQS and SNS for workflow and failure notifications
This provides a serverless architecture for video encoding by leveraging Lambda and ECS together.
AWS Lambda Practical Interview Questions
Q19. Write a Lambda function that converts a string to uppercase.
To write lambda function that converts string to upper case:
- Importing the ‘json’ Module: Import the ‘json’ module. This module is used later in the function to format the response in JSON format.
- Definition of the ‘lambda_handler’ Function: AWS Lambda functions require an entry point, and in this code, it’s the ‘lambda_handler’ function. This function is automatically called when the Lambda function is invoked. It takes two parameters:
eventandcontext. - Extracting Input from ‘event’: The ‘event’ parameter is expected to contain input data. In this case, it assumes that the input is provided as a JSON object, and it extracts the ‘input’ field from this JSON using
event['input']. - Converting the Input String to Uppercase: The extracted ‘input_str’ is then converted to uppercase using the
.upper()method. This method is a built-in function for strings in Python that returns an uppercase version of the original string. - Creating the Response Dictionary: Next, a response dictionary is created with two key-value pairs:
'statusCode': This field is set to 200, which is a common HTTP status code indicating a successful request.'body': The ‘body’ field contains a JSON object with an ‘output’ field. The ‘output’ field contains the result of the string conversion to uppercase.
- Returning the Response: Finally, the ‘lambda_handler’ function returns the response dictionary. This response can be used by other AWS services, API Gateway, or any other service that invokes this Lambda function.
# Lambda function to convert string to upper case
import json
def lambda_handler(event, context):
input_str = event['input']
output_str = input_str.upper()
return {
'statusCode': 200
'body': json.dumps({
'output': output_str
})
}Q20. Write a Lambda function triggered by the DynamoDB stream to increment a counter on row updates.
The major components of Lambda function triggered by the DynamoDB stream to increment a counter on row updates are:
- DynamoDB Stream Trigger: AWS Lambda function is designed to be triggered by a DynamoDB stream. DynamoDB streams capture changes (inserts, updates, deletes) in a DynamoDB table, and this Lambda function responds to these events.
- Incrementing a Counter: For each record (event) in the DynamoDB stream, the Lambda function extracts the primary key value (‘id’) and uses it to update the corresponding DynamoDB item. It increments the ‘counter’ attribute by 1 using an
UpdateExpression. - Response Acknowledgment: After processing all the records in the DynamoDB stream, the Lambda function returns a response with a status code of 200. This response is typically used for acknowledgment purposes to indicate the successful execution of the Lambda function in response to the DynamoDB stream events.
// Lambda function triggered by the DynamoDB stream to increment a counter on row updates.
import json
def lambda_handler(event, context):
for record in event['Records']:
primary_key = record['dynamodb']['Keys']['id']['N']
table.update_item(
Key={'id': primary_key},
UpdateExpression='SET counter = counter + :incr',
ExpressionAttributeValues={':incr': 1}
)
return {
'statusCode': 200
}Q21. How would you deploy a Lambda function using the CloudFormation template?
Steps to deploy lambda function using cloud formation:
- Define the AWS::Lambda::Function resource in the template.
- Specify handler, runtime, code S3 URL
- Handle permissions via AWS::IAM::Role.
- Configure VPC, environment variables
- Output logical function name to reference in other resources
- Use transform directive to enable Serverless Application Model (SAM)
- Utilize CloudFormation parameters for dynamic configuration.
Q22. How would you implement blue-green deployment for the Lambda function?
To implement blue-green deployment for the lambda function:
- Create two function versions: Blue and Green.
- Set up alias mapped to Blue version.
- Configure API Gateway to point to alias.
- Deploy the Green version and test it thoroughly.
- Gradually shift alias traffic to Green.
- If there are issues, route all traffic back to Blue.
- Use CloudWatch metrics to monitor canary deployments.
Q23. How can you invoke a Lambda function from a client application?
To invoke a lambda function from client application:
- Install AWS SDK for the language of choice.
- Configure SDK credentials and region
- Call invoke() API, passing function name, payload, parameters.
- Handle AuthN/AuthZ either via IAM roles access keys.
- Validate response and handle errors/exceptions.
- Use SDK configurable retries for transient errors.
Additional AWS Lambda Interview Questions
- How does AWS Lambda handle concurrency, and what is the significance of “reserved concurrency” for a Lambda function?
- AWS Lambda functions have cold starts and warm starts. What are they, and how do VPCs influence Lambda cold start times?
- Describe the difference between AWS Lambda Layers and AWS Lambda Extensions. When would you use each?
- How would you set up a Lambda function to process records from an Amazon Kinesis stream, ensuring order and at least one delivery?
- AWS Lambda has built-in retry behaviour for asynchronous invocations. How can you customize this behaviour, and what are potential pitfalls to be wary of when adjusting these settings?
- What are the primary considerations when migrating a long-running EC2-based application to a serverless architecture using AWS Lambda?
- How does AWS Lambda handle state persistence between invocations, and how would you implement stateful processing in a serverless application?
I hope You liked the post ?. For more such posts, ? subscribe to our newsletter. Check out more terraform interview questions


