

For application having very large database, the database is sharded and stored at various locations. To search any specific type of data in database is one of the biggest challenge. Using linear or binary search or searching on index values can make the search query inefficient. To solve this problem hashing in dbms is used. It uses key value pair where key is hash of data object generated by hash functions to locate data in minimum amount of time.
In this article we will look into detail about hashing in DBMS.
Hashing In DBMS
Hashing in dbms is technique in which address of data or data blocks where actual record is stored is calculated using hashing function. The hash function uses any column (generally primary key) of record to generate address of data block/bucket. The hash function can be simple mathematical equation or complex function and parameters are decided such that hash collisions or bucket overflow is minimised.

Terms Related To Hashing In DBMS
- Data bucket – Data buckets or data blocks are memory addresses where the records are stored. It is also known as Unit of Storage.
- Key: A DBMS key is an attribute or set of an attribute which helps you to identify a row(tuple) in a relation(table). To know more about DBMS keys refer this article.
- Hash function: A hash function, is a mathematical equation which maps search keys to the data bucket where actual records are placed.
- Hash index – It is a key generated by hash function which maps to data bucket where record is located.
- Bucket Overflow: When more than one record maps same hash index, it is called bucket overflow or hash collision.
- Directories – These are the containers that store pointers to the buckets. Each bucket has an “id” associated with them.
- Global depth – Global depth can be defined as the number of bits in directory id. This is used in dynamic hashing to increase/ decrease the size.
Types of hashing in dbms
There are majorly two types of hashing in dbms
- Static Hashing
- Dynamic Hashing
Static Hashing In DBMS
Static Hashing in DBMS is a type of hashing in which for any key K the hash function gives same output or memory address. This means the number of data buckets will remain same. This process of static hashing is also referred to as ‘static scatter storage addressing’, as it involves gathering all the scattered static data by their address and mapping the same to be rearranged in an orderly fashion.
In the below example we can see the records R1,R2,R3,R4 with primary key column as A are passed to hash function. The primary key column is then used by hash function to generate data bucket address where record is stored. After the hash function is executed on the records in the table, the records are then placed in the proper addresses in the storage memory.

Operations In Static Hashing in DBMS
- Insertion: To insert new record, bucket address is calculated using one of the fields of record(primary key) as key and passed to hash function, the output of the function is inserted into hash table.
- Searching: To search a record we will use the same hash function to get the bucket address of the record and retrieve the data from there.
- Deletion/ Update – To delete or update a record from the table we will firstly search for that record using above algorithm and then simply delete/update it from that location.
Dynamic Hashing in DBMS
One of the main drawbacks of static hashing is that it is not flexible on space i.e number of data buckets remain same and it does not expand or shrink as the size of the database expands or shrinks.Dynamic hashing solves this problem that allows on demand addition and removal of data buckets.That is why it is called extended hashing.
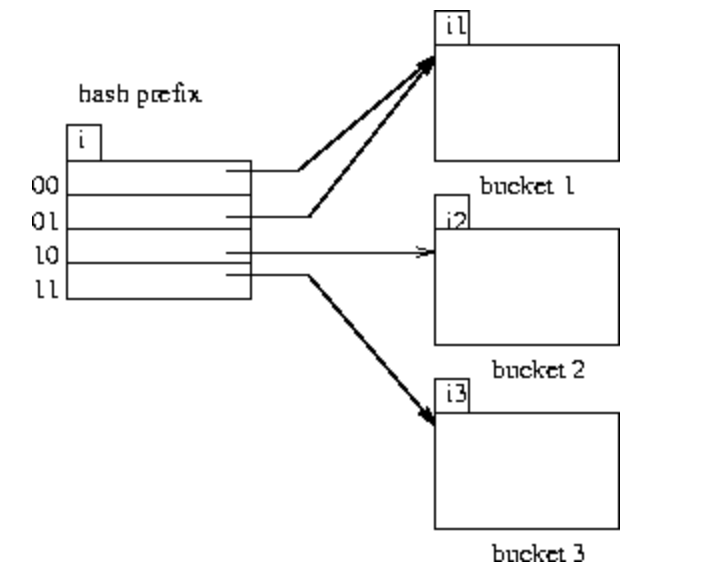
The hash function is chosen such that it is uniform and random and generates value over large range i.e d-bit binary integers where d is usually 32 or 64.
All the 2^32 buckets are not generated in one go instead buckets are created on demand and only some bits are used initially. The i bits or global depth are used as an offset to uniquely identify data buckets which grows and shrinks with size of database.
Let’s understand this using example.
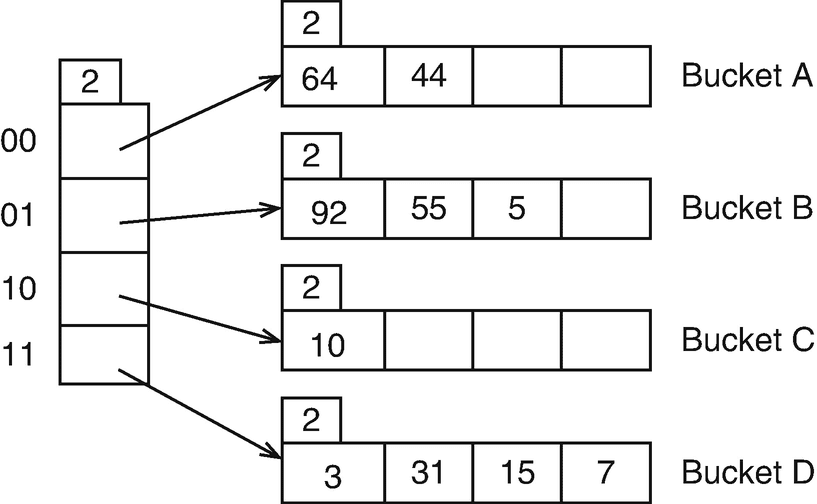
Let’s assume global depth size is 2. Therefore we will only use 2 bits of hash function output to map to data buckets.Therefore the obtained values are 11,00,11,10.
Searching:
- Calculate the hash address using hash function and taking one of the fields(typically primary key) as key and convert it to binary. Let’s say output is 11011101.
- Take i LSB bits equal to global depth size. If k =2 then we have 01.
- Navigate to bucket with id 01 and search the record.
Insertion/Deletion/Updation:
The above three steps are repeated and operation is performed accordingly.
Increasing Bucket Numbers
Now suppose are application went viral and database size increased enormously. So now to add more buckets we can simply use more bits i.e increase global depth size.
Earlier we were using 2 LSB bits, so to increase number of buckets we can now start using more bits from hash output.
Dealing With Hash Collisions
Choosing right hash function and its parameters to avoid hash collision become very important to reduce hash collision. But to eliminate hash collision completely is impossible. Various techniques are used to deal with hash collisions:
Open Chaining: In Open Chaining, all elements are stored in the hash table itself. Two techniques are used
- Linear Probing – Linear probing is a fixed interval between probes. In this method, the next available data block is used to enter the new record incase of hash collision.
- Quadratic probing– It helps you to determine the new bucket address. It helps you to add Interval between probes by adding the consecutive output of quadratic polynomial to starting value given by the original computation.
Separate Chaining: The idea behind separate chaining is to implement the array as a linked list called a chain. When multiple elements are hashed into the same slot index, then these elements are inserted into a singly-linked list or array which is known as a chain.
Double Hashing: In this method two hash functions are used. The input of second hash function is the output of the first.
Conclusion
In this article we discussed about various types of hashing in dbms and also discussed various ways to resolve conflicts in hashing in dbms.
Got a question or just want to chat? Comment below or drop by our forums, where a bunch of the friendliest people you’ll ever run into will be happy to help you out!


