

SQL is a shorthand in the form of Structured Query Language. SQL for developers is utilised to communicate with databases. . SQL statements can be used to carry out tasks like updating the database’s data or to extract data from a database. A few popular relational database management systems that use SQL for developers are: Oracle, Sybase, Microsoft SQL Server, Access, Ingres, etc. Although the vast majority of database systems utilise SQL however, a majority of them also come with specific extensions that are generally only utilised within their systems. But, the basic SQL commands like “Select”, “Insert”, “Update”, “Delete”, “Create”, and “Drop” can be used to perform almost anything you need to do with databases.
In this post we will look into some of the interview questions on SQL that are generally asked in almost every interviews.
Explain the term RDBMS?
The relational management of databases (RDBMS or simply RDB) can be described as a popular kind of database that is essentially a program which allows us to build updates, deletes, and create the database in a relational manner. Relational database is type of database which stores and retrieves information in tabular format that is organised by columns and rows.
Databases with relational structure have the capacity to handle a multitude of data and complicated queries. Multiple tables are a common feature of the most modern database. The data is usually stored in multiple tables, sometimes referred to as relations. These tables are separated into rows, also known as rows and columns (fields). There could be millions of rows within the database.
Define Normalization?
Normalization is the procedure of reorganizing the data in databases so that it satisfies two essential prerequisites:
- There is no redundant data. All data is kept in one location.
- Data dependencies are logical. All related data elements will be saved together.
Normalization is crucial for many reasons, but most importantly because it lets databases use the smallest amount of disk space feasible, which results in improved performance. Normalization is also referred to by the name of data normalization.
What are the different forms of normalization?
| Normal Form | Description |
|---|---|
| 1NF | A relation is in 1NF if it contains an atomic value hence, there are no repeating groups. To normalize a relation that contains a repeating group, remove the repeating group and form two new relations. |
| 2NF | A relation will be in 2NF if it is in 1NF and each non-key attribute of primary key must be fully dependent on the entire primary key and not on a subset of the primary key i.e., there must be no partial dependency or augmentation. |
| 3NF | A relation will be in 3NF if it is in 2NF and no transition dependency exists, a non-key attribute may not be functionally dependent on another non-key attribute. |
| BCNF | Boyce-Codd normal form is a special case of 3NF. A relation is in BCNF if, and only if, every determinant is a candidate key. |
| 4NF | A relation will be in 4NF if it is in Boyce Codd normal form and has no multi-valued dependency. |
| 5NF | A relation is in 5NF if it is in 4NF and not contains any join dependency and joining should be lossless. |
What is the stored procedure?
A stored procedure can be described as a collection comprised of SQL statements that were earlier created and stored within the database of the server. The stored procedures can accept input parameters to ensure that a single process can be utilised over the network by multiple clients with different input parameters. This is known as a subroutine, or subprogram of the standard computer language that was written by the server and then stored inside the database.
Every procedure in SQL Server is always has the name, the parameter lists, as well as Transact-SQL-specific statements. It is the SQL Database Server stores the stored procedures in name-based objects.
To create a stored procedure the syntax is fairly simple:
-- Interview Questions on SQL: Stored Procedure
CREATE PROCEDURE <owner>.<procedure name>
<Param> <datatype>
AS
<Body>What is a Trigger?
A trigger is an SQL procedure that triggers an action whenever an event (INSERT OR DELETE) occurs. Triggers are stored within and controlled by the DBMS.Triggers are used to preserve the integrity of referential data by altering the data in a methodical manner. Triggers cannot be invoked or executed, the DBMS automatically triggers the trigger upon the occurrence of a modification in the data of the table it is associated with.
Triggers can be thought of as like stored procedures because both contain the logic of a procedure that is stored in databases. Stored procedures however do not have an event-drive component and aren’t tied to a particular table like triggers are. They are executed by calling a CALL on the method whereas triggers are executed implicitly. Additionally, triggers can be used to execute stored procedure.
-- Interview Questions on SQL: Triggers
create trigger [trigger_name]
[before | after]
{insert | update | delete}
on [table_name]
[for each row]
[trigger_body] What are Views?
Views are virtual table whose content is determined through the sql query. Like a table, view is a collection of named rows and columns of data. Without indexing or otherwise, a view will not exist as a list of data values in databases. The columns and rows of view are derived from tables that are being referenced in the query. They are generated when a view is referenced.
The query that creates the view can reference any of the tables, or from different views within the database at hand or from other databases. Distributed queries may be utilised to define views that draw data from different heterogeneous sources. This is beneficial when, for instance, you wish to mix similar structured data from multiple servers that each store data for a specific area of your business.
-- Interview Questions on SQL: Views CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition;
How do you define Index in SQL?
They are special tables that the database search engine could make use of to speed up retrieval of data. In simple terms an index acts as a pointer of the data contained in tables. A database index is identical to an index found in the back of the book. There is the possibility of creating an index for the one or more columns of an existing table.
Every index is assigned a name. Users are not able to see indexes. They are utilised to improve the speed of queries. Effective indexes are among the best methods to increase the performance of a database application. Table scans occur when there isn’t an index to aid with a query. When a table scan is performed, SQL Server examines every row in the table to determine the query’s results. Table scans are often necessary however, on tables with a large number of rows scans can have a significant impact on the performance.
Explain Types Of Indexes
- Clustered Indexes
- Clustered indexes are used to sort and store data rows in the table or view according to their key values. They are columns defined in the definition of an index. There is only one clustered index for each table since the rows of data are stored in only one order.
- The only way that rows of data in a table will be stored in order of sorting is when the table has a clustered index and such table is called clustered table. If the table is not clustered index, then its rows of data are kept in an unorganised structure called heap.
-- Interview Questions on SQL :Create Clustered index index
create Clustered index IX_table_name_column_name
on table_name (column_name ASC) - Non Clustered Indexes
- Non-Clustered Index is similar to the index of an actual book. A book’s index comprises of a chapter’s name as well as a page number. If you wish to read a chapter or topic, you can simply go to the appropriate page with the help of the indexes of the book. It is not necessary to look through every single page in an entire book.
- The data is saved in one location, while the index is stored in a different location. Because, the non-clustered index as well as the data are stored separately, you could have multiple non-clustered indices within the table.
-- Interview Questions on SQL :Create Non-Clustered index
create NonClustered index IX_table_name_column_name
on table_name (column_name ASC) What is the main difference between a clustered and non-clustered indexes?
Clustered Index is a particular kind of index that alters how records within the table are physically stored. Thus, a table can only have the one index that is clustered. The leaf nodes in clustered index contain data pages.
A non clustered index is a particular kind of index where the logical arrangement of the index doesn’t correspond to the physical rows’ order on the disk. The leaf node in the nonclustered index doesn’t comprise of data pages. Instead the leaf nodes are made up of index rows.
What are cursors?
Cursor is a type of database object that is used by applications to alter data within an array on a row-by-row basis, in lieu of common SQL commands that run across all rows within the set at the same time.
To be able to use a cursor , we have to follow these order
- Declare cursor
- Open cursor
- Retrieve row from the cursor Process the fetched row Close the cursor
- Deallocate cursor
What is the difference between a Primary and Unique Key?
The primary key, as well as the unique key guarantee the uniqueness of the column which they are based. However, by default, primary keys creates a clustered index of the column, whereas unique is a non clustered index automatically. A further difference is that primary key doesn’t permit NULLs, while unique key can accepts NULL value. A table can have only one primary key whereas there can be multiple unique key on a table.
What is the difference between TRUNCATE and DELETE commands?
The Delete command eliminates rows from tables in accordance with the conditions which we specify by using a WHERE clause. Truncate will remove all rows in the table. DELETE statement is used when we want to remove some or all of the records from the table, while the TRUNCATE statement will delete entire rows from a table.
| TRUNCATE | DELETE |
| TRUNCATE is more efficient and consumes less processing and transaction logs | DELETE is less efficient and consumes more processing and transaction logs |
| TRUNCATE erases the data through locating the data pages that are used to store table’s information, and only the page’s deallocations are noted on the transaction log. | DELETE takes rows out one at a time , and adds an entry to the log of transactions for every row deleted. If you wish to keep an identity counter you can use DELETE instead. |
| Since TRUNCATE TABLE has not been recorded, it isn’t able to trigger an event. | DELETE activates Triggers. |
| TRUNCATE is not able to be rolled back. | DELETE is able to be Rolled back. |
| TRUNCATE can be described as DDL Command. | DELETE can be described as DML Command. |
What is the difference between Stored Procedure and Function?
| User Defined Functions | Stored Procedure |
| UDF can return only one value which is mandatory | SP can return zero, one or multiple values |
| UDF is only able to accept inputs, not output parameter | Stored procedure is able to accommodate both outputs and inputs parameter |
| There are no transactions permitted in functions in UDF | In stored procedure, transactions are permitted. |
| Catch blocks are not able to be used in UDF | SP supports catch blocks |
| Table variables are the only ones that are allowed to be used in UDF and not temporary tables. | The stored procedure is allowed to create table variables as well as temporary tables. |
| UDF doesn’t allow saved procedures to be called by functions. | Stored procedures permit the calling of functions. |
| UDF can be utilised in join clauses | Stored procedures cannot be used in join clauses. |
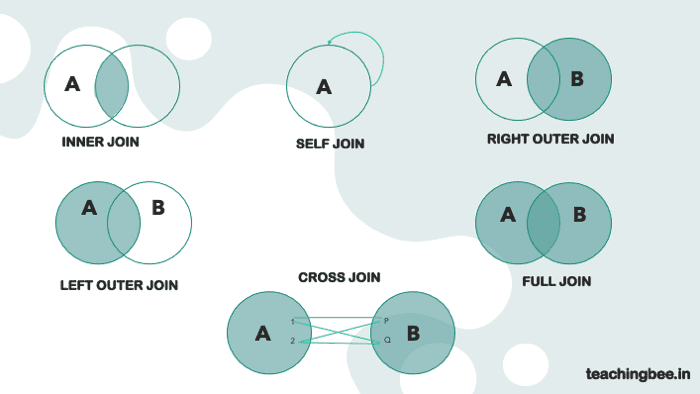
What are different types of JOINS in SQL?
Joins are utilised in queries to show how tables are linked. Joins allow you to select data from one table based on the data in another table.
Join types: INNER JOINs, OUTER JOINS, CROSS JOINS. OUTER JOINS also are classified as LEFT OUTER Joins, RIGHT OUTER JOINS, and FULL OUTER JOINS.
What are differences between A WHERE and HAVING CLAUSE?
| WHERE CLAUSE | HAVING CLAUSE |
| It cannot contain aggregate functions | It can contain aggregate functions |
| It can be used with SELECT, UPDATE, DELETE statements | It can only be used with SELECT statements |
| It can be used with/without GROUP BY clause | It cannot be used without GROUP BY clause |
| It selects rows before grouping. | It selects rows after grouping. |
What are Sub Queries and its properties?
Subqueries can be simply defined as a query within another query. Sub-queries are executed by wrapping it in an array of parentheses. Sub-queries generally give a single row an atomic number, but they are also used to evaluate results against multiple rows using an IN keyword.
Properties of SubQuery
- Sub-queries must be enclosed in parenthesis.
- Sub-queries must be placed in to the upper right-hand of the operator
- A sub-query should not contain an ORDER-BY clause.
- A query can have multiple sub-queries.
Can a stored process call itself or a recursive stored procedure?
Yes. Since Transact-SQL allows recursion, you can write stored procedure which call themselves. Recursion is an approach to problem solving that involves arriving at by repeatedly applying it to subsets of the challenge. The most common use of recursive logic is the execution of numerical computations that are prone to repeated evaluation using the same process steps. Stored procedures can be nestled when one stored procedure calls another or executes managed codes through an CLR routine such as type or aggregate. It is possible to nest stored procedure or managed code references to up at 32 levels.
What’s @@ERROR?
The auto-generated variable @@ERROR gives the error code of the Transact-SQL transaction that was last executed. If there is no error, then @@ERROR returns the number zero. Since @@ERROR resets every time a Transact-SQL query is executed It is necessary to save it to a variable in case it is required to process it again after examining it.
How do you define log shipping?
Log shipping refers to the method of automating the backup process of the transaction log and database files on the production SQL server, and later returning them to an off-site server. Enterprise Editions can only support log shipping. Log shipping is a process where the transactional log file of the server that is being used for log shipping will be automatically inserted into that backup database of another server. In the event that one of servers fails another server will also have the same database and could be utilized to create the Disaster Recovery plan. Log shipping is that it can automatically save transactions throughout the day, and then automatically restore them to the standby server at a predetermined time intervals.
How can you tell the difference between global and a local Tables?
The local table is present only during the duration of a connection or, if specified in a compound statement for the entire duration that the phrase is in the compound.
Global temporary tables is in the database forever. However, the rows exist only for a particular connection. After connection has been shut down, the information in the table that is global is deleted. But, the table’s definition is retained by the database and can be accessed when it is opened again.
What are the various types of replication?
The various types of replication are:
- Full table replication
- Transactional replication
- Snapshot replication
- Merge replication
What are the primary features of master models, msdb, model tempdb databases?
The Master database contains information for all databases that are in the SQL Server instance and is the glue that binds the engine. Since SQL Server cannot start without having a master database that is functioning it is essential to administer the database carefully.
The database msdb stores details about database backups, SQL Agent information, DTS packages, SQL Server jobs, as well as some information related to replication, including log shipping.
The tempdb stores temporary objects, such as local and global temporary tables as well as stored procedures. The model is basically the template database used for creating any user databases that is created within the context of.
What are the primary key and foreign keys?
Primary keys are unique IDs of each row. They should contain unique values and should not be non-null. Because of their significance in relational databases Primary keys are the most important among all the keys as well as constraints. A table is able to have only one primary key.
It is a foreign Key is a key in a database that is utilised to connect two tables. It is used to link two tables. FOREIGN KEY constraint is used to identify the relationship between tables in the database by referencing the column or set of columns within the child table, which contains the foreign key. It is linked with respect to PRIMARY KEY column, or set of columns within the parent table.
What is integrity of data? Define the constraints?
Data integrity is a crucial attribute of SQL Server. It is a crucial feature in SQL. If properly used it guarantees that data integrity is maintained.
precise, accurate reliable, accurate, and legitimate. It also serves as a trap for invisible bugs within the applications.
A Primary KEY constraint can be described as a distinct identifier of each row of the database table. Each table must have an initial key constraint that will identify each row as a unique entity. just one primary key constraint could be made in each table. Primary key constraints serve to ensure integrity of the entity.
A UNIQUE constraint ensures the exclusivity of the values within the columns, which means that there are there is no chance of entering duplicate values. Unique key constraints serve to protect integrity of entities as the main key constraint.
A FOREIGN key constraint blocks actions that might end links between tables that have the data values that correspond. The foreign key of one table is linked to an primary key in another table. Foreign keys block actions that could create rows with foreign key values if there aren’t primary keys that have this value. Foreign key constraints help ensure the integrity of referential references.
A CHECK constraint can be employed to limit the amount of data that can be included in columns. Check constraints are employed to ensure the integrity of the domain.
The NOT NULL restriction ensures that the column cannot take null value. These constraint is used to ensure integrity of the domain, similar to check constraints.
What is De-normalization?
De-normalization is a process of trying to improve efficiency of databases by introducing redundant data. Sometimes, it is necessary due to the fact that current databases do not properly implement the relational model. A truly relational DBMS could permit an entirely normalized database at the logical level and provide physical storage for data that is optimized to provide high-performance. De-normalization is a method for moving from higher to lower normal
Is Self Join a thing?
This is the situation where a table joins itself using an alias or two in order to prevent confusion. Self-joins is of any kind provided that the tables joining are identical. Self joins are distinct in that it has the relationship of just one table. The most common scenario is when a company has an organizational structure of reporting that is hierarchical, where employees report to an individual.
What exactly is Cross Join?
A cross-join that doesn’t have a WHERE clause results in the Cartesian result set of the tables used in the cross-join. The size of the Cartesian results set for a product is the amount of rows from the initial table, multiplied by number rows of the table. A typical scenario is when a the company is looking to integrate every merchandise with an pricing table so that they can evaluate each product’s price.
What exactly is DataWarehousing?
Data Warehousing means that the information in the database is structured so that all elements of the database that relate to the same object or event are connected. The changes made to the data stored within the database are monitored and recorded, so that reports are produced with time-lapsed changes;
The data stored in the database will never be erased or rewritten, and once committed, the information is not movable, read-only, but is kept for future reports and the database is populated with data from all or most of an organisation’s applications for operation and is made uniform.
Conclusion
These were some of the interview questions on sql. Hope you got the idea about sql questions asked in technical interviews.
Got a question or just want to chat? Comment below or drop by our forums, where a bunch of the friendliest people you’ll ever run into will be happy to help you out!


