

Introduction
In the modern age of Big Data, popular social media platforms, as well as IoT sensors, the datasets are enormous. If the data is kept in a single database, queries can become slow. The overall performance of the system is affected. This is the time when the benefits of sharding database are realized.
A single logical database is divided into multiple databases which are distributed over multiple machines. If a request is requested and only one or handful of computers may be involved in the process of processing the query. Sharding database allows efficient scaling and managing of massive databases. There are many methods to break a large dataset into shards.
Sharding database is feasible with the use of both SQL as well as NoSQL databases. Certain databases offer out-of-the-box capabilities for sharding. Other middleware and tools are available to help with the process of sharding.
What is Sharding in Database?
It is the method of breaking huge tables into smaller pieces called shards . They are then distributed over multiple servers. A shard is basically an horizontal data partition, which contains only a portion of the data set, and thus serves as part of the total work. The concept is to spread data that cannot be accommodated on one node on a cluster of databases nodes. The term “sharding” is also known as horizontal division. The distinction between vertical and horizontal originates from the traditional tabular view of the database. A database may be divided vertically, storing various column rows in a separate one database or it can be split horizontally storage of rows from the same table across multiple database nodes.
Why to Consider Sharding Database
The issue with keeping lots of data on a relational database is that database is required to reside on a single server. If you exceed the capacity of one server you’re stuck. There’s no way to harness the power of several servers. This is where sharding comes into play. The term “sharding” refers to finding a method to divide your data to allow you to save portions of it on different servers. It’s exactly what Encyclopaedia Britannica did when they were overwhelmed with pages to put to one volume, they divided it into volumes.
- Database sharding can help us help with horizontal scaling. We can thus add more servers to the server and share the load in order to expand the applications.
- Faster query response time. Without sharding of the database it is necessary for the database to analyze a query against every row, and this can result in a massive disadvantage. However, with sharding instead being able to traverse all rows it is necessary to go through only a handful of rows.
- Sharding can make maintenance easier.
- Sharding databases eliminates the need to one source of failure and increases the reliability of our application.
- Reduced costs. The addition of more memory and storage to one computer (Vertical scaling) is costly while using a number of nodes with lower computing power are less expensive.
Only Consider Sharding Database If
- Your database’s update rate is near or even exceeding the capacity of the top specification server you could afford to buy.
- You’re already outsourcing all of your read queries, reports backups, etc. read-only replicated slaves.
- You’ve done functional partitioning in order to transfer any non-essential or unrelated heavy workloads that require updates off of your main server.
Sharding vs Partitioning

Sharding vs Partitioning, both these terms are often used interchangeably when discussing databases. I found this to be among the more difficult aspects of learning about this subject because they are employed interchangeably and there’s some overlap between the two terms.
Partitioning is a word used to describe the process of breaking your data elements logically into different entities for purposes of efficiency, availability, or maintaining.
Sharding database is the same as “horizontal partitioning”
When you shard a database you create duplicates of the schema and then split what data is stored on each shard according to the shard’s key. Lets consider database sharding example, Suppose if i have a large customer databse, I could shred my customer database by using CustomerId as a key shard which would store ranges from 0 to 10000 in one shard, and 1000-2000 in another shard. When selecting a shard’s key and the DBA will usually look at patterns in data access along with space concerns to make sure that they’re distributing the burden and space equally.
“Vertical partitioning” is the method of breaking up the data that is stored within one entity into multiple entities.
This is due to space and to improve performance. For instance, a customer may have only one billing address, but I may decide to place the billing information in another table, with an ID reference, to give me the ability to transfer the information to a different database, or into a different security contexts, etc.
To sum up, partitioning is a general word that simply means to divide your logical entities in different physical entities to improve the sake of performance or availability, or for some other reason. “Horizontal partitioning”, or sharding, is the process of replicating the schema and partitioning the data on the basis of the shard keys. “Vertical partitioning” involves dividing up the schema (and the data is taken along with the schema).
Different Strategies For Sharding Database
Sharding can take place in many ways, employing different methods. Let’s look at them in the following paragraphs.
Key Based Sharding
To understand the concept of key-based sharding we’ll need to comprehendor revisit the concept of an hash function. In this course we’ll assume that the function of a hash to be an opaque box that assigns values. It accepts a particular piece of data as input and produces a discrete number which is the same as the input. In this scenario the value is referred to as a hash value.
In key-based sharding from a column of the database table are utilized. The values are then plugged in to the function hash. Its output value decides which shard data should be stored on. The hash value calculated will be the ID of the shard that determines the shard on which the data is stored on.
The numbers of the functions are directly from one column. It is possible to think of them as primary keys. They create the unique identifier of every row of the table. The values that are found in this column are referred to as”shard keys. It is important to note that the shard key has to have the same value and does not change in time. If it is not, the update processes could result in errors and also add more work.
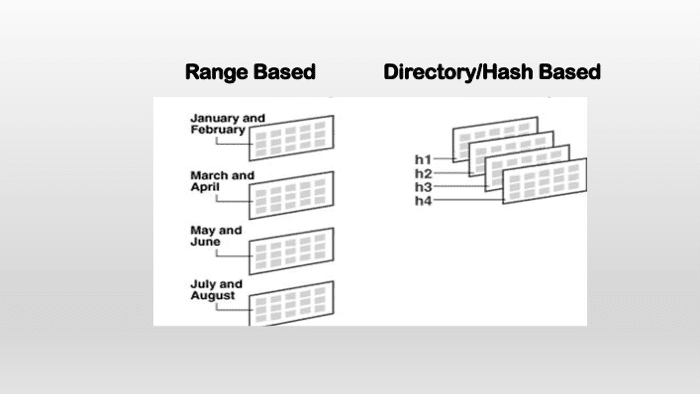
Range Based Sharding
The range-based method involves sharding data according to a defined number of values of an attribute. This approach is simple to comprehend and apply.
Imagine a database that holds details about customers, including the amount of goods they purchased from the shop. Suppose we define 2 ranges. The first one is between 1-25 and the other range is 25-50 for the amount of products bought. This results in two shards. Data will then be separated in accordance with the value of the number into tables that are corresponding to them.
Directory-Based Sharding
Directory-based sharding uses a lookup table which maintains track of which shard is holding what information. Also, it provides a one-to-one mapping the data to the shard it’s kept in.
A column from the initial table is picked as the Shard Key (just like we do for Key-based Sharding). Each shard is assigned a unique shard ID that tells which shard is hosting the information with its associated key shard. This way the rows of all rows of the table are divided into distinct shards.
Hierarchical
The combination of column and row is employed as the shard-key. Strategies for sharding previously mentioned can be employed on the key.
Entity Groups
To make it easier to perform queries across multiple tables this technique places tables in one shard. This ensures greater consistency. For instance, all the data about a user are stored within one shard.
Choosing The Right Shard Key
What should I consider when choosing the right key for a sharding database?
The choice of a shard key can be an important choice. Once you’ve made the choice, it’s difficult to alter this later.
Following things to be considered before selecting shard key
- Think about how your choice will impact the current schema and queries, as well as query performance. The choice must be compatible with the present and future business instances.
- Determine the most important parts of the data as well as clustering patterns.
- To maximize efficiency, the type of data used by the shard key should be an integer.
- Sharding should balance two demands to minimise cross-partition queries, and spread the load equally through sharding to the correct level of granularity.
- Shard key should be located in the column (SQL) or field (NoSQL) that meets the following requirements:
- Stability: It nearly never changes. In the event that it does, we may have to pay for costly data movement from one shard to the next.
- High Number of Values: It should come with several unique characteristics w.r.t the amount of shards.
- Steady: The value does not fluctuate or decrease monotonically.
Drawbacks Of Sharding Database
- Adds complexity to the system: Implementing an sharded architecture for databases is a difficult task. If done incorrectly it is a high possibility that the sharding process could lead to data loss or damaged tables. Sharding database can have a major effects on your team’s workflows. Instead of managing data and accessing it at a single entry point Users must manage their information across multiple shards that could be detrimental to certain teams.
- Rebalancing data: There are times when one shard is bigger than the other and becomes unbalanced. This can also be referred to as a database hotspot. In this situation, the benefit of sharding database are cancelled out. The database will likely required to be re-sharded in order to ensure an evenly distributed data distribution. Rebalancing needs to be planned from the beginning otherwise shifting the data between shards to the next shard can take a lot of time.
- Joining data from different shards: In order to implement certain complicated functions, we might need to draw a large amount of data from various sources that are spread across several shards. We aren’t able to make an inquiry and receive data from several shards. It is necessary to make multiple queries to various shards, and then collect all the results and then merge them.
- No native support: Sharding is not natively supported by all databases engines. This is why it is often required to “roll your own”. This means that the documentation needed on sharding as well as tips for troubleshooting issues are typically difficult to locate.
Some Best Practices For Sharding Database
- Sharding is a possibility only when other options have not worked. Principal reasons for sharding databse include restrictions on processing, storage and network bandwidth, as well as regulations and proximity to the geographic. Data analytics usually takes place across the entire dataset. This is why sharding is suitable to Online Transaction Processing (OLTP) instead of Online Analytical Processing (OLAP).
- Tables that have foreign key relationships can have the same shard key. To ensure that primary keys remain distinct across all shards in future OLAP Shard IDs may be added with primary keys.
- Sharding is a possibility to combine with replication. In fact, to ensure high availability, it’s typical to duplicate shards. You can even duplicate information across shards, for instance as duplicate chat messages between both the sender’s and recipient’s shards.
- Examine the performance of each shard in terms of the utilisation of CPUs, memory and read/write performance and think about resharding in the event of hotspots.
Conclusion
Sharding databse is a good option for those who want to increase the size of their databases horizontally. However, it can add an enormous amount of complexity and can create more possible failure points to your app. The use of sharding is possible for certain, but the time and effort required to build and maintain the sharded structure could outweigh the benefits for other.
I hope through reading this article, you got to understand the advantages and disadvantages of shredding. In the future, you will be able to utilise this knowledge to make a better choice about whether the sharding database is suitable for your needs.
Got a question or just want to chat? Comment below or drop by our forums, where a bunch of the friendliest people you’ll ever run into will be happy to help you out!


