

In an always-on digital world, system availability is not just a technical concern but a key business priority. Whether it’s an e-commerce site processing millions in sales or a bank facilitating real-time transactions, downtime directly translates to lost revenue and eroded trust. That’s why highly available systems capable of providing uninterrupted service even in the face of failures are essential. But what exactly does Availability in system design mean and it is measured and how to improve it.
In this post we will answer all these questions in detail by discussing every aspect of availability in system design.
What is Availability In System Design?
Availability in system design refers to the percentage of time a system remains functional and operational under normal conditions. It measures a system’s percentage of uptime over a given period. It is a vital element of system reliability, ensuring that users can access the system and its services when they need them.
Let’s see some of the examples where the availability of the system plays an important role :
- E-commerce websites – Sites like Amazon, eBay, and Flipkart rely on high availability to drive sales and traffic. Their infrastructure is designed to handle load spikes during peak events like Black Friday sales.
- Banking systems – Banks rely on online banking systems and ATMs to provide 24/7 access to customer accounts and financial services. Downtime can severely impact customers
- Streaming services – Netflix, Hulu, and other streaming services require high availability to deliver uninterrupted video to millions of concurrent users.
Thus, availability is a key requirement across many industries dealing with critical systems and high traffic volumes. Careful system design with redundancy is essential to meet customer expectations and business needs.
Importance of High Availability in Distributed Systems
High availability is important for distributed systems for the following reasons:
- Fault tolerance – Distributed systems consist of many components spread across locations. Component failures are inevitable. High availability provides seamless failover and graceful degradation in case of outages.
- Meeting SLAs – Many distributed systems like cloud services promise uptime in SLAs of 99.99% or higher. High availability is necessary to meet these contractual commitments. We will see in detail what SLAs and 99.99% mean in a bit.
- Mitigating revenue loss – Downtime in distributed systems directly translates to lost business, transactions, and revenue. Maximizing availability minimizes financial losses.
- Ensuring quality of service – Users have little tolerance for poor performance or slow responses. Availability ensures optimal QoS and uninterrupted experience.
- Minimizing recovery time – Failures are restored quickly with minimum effort in highly available systems. This maintains productivity and customer satisfaction.
- Reducing disruptions – Lack of availability frequently disrupts operations and workflows. Distributed systems with high uptime minimize disruptions.
Thus we can say that availability is not just a technical requirement but a business need for large-scale distributed systems. It directly impacts user experience, system scalability, operational costs, and organisational goals. Hence high availability is a central design concern.
How to measure availability in distributed systems?
Some common ways to measure availability in system design:
- Uptime percentage – This basic metric calculates the total time a system remains operational divided by the total period. 95% uptime means the system was available 95% of the total time.

- Downtime per year – Measuring total downtime episodes and duration per year indicates system reliability over time. Excellent systems strive for less than 4 hours of downtime annually.
Downtime per year = Number of downtime incidents x Average downtime per incident
This measures system reliability over time. Excellent systems target < 4 hours of downtime per year.
Measuring Availability with Nines
Availability is often measured in terms of “nines” representing uptime percentage. Here is an overview of availability with nines and a table showing downtime per year:
Nines for Availability
- 9 or 99% uptime = 8.77 days downtime/year
- 99.9% (three nines) uptime = 8.77 hours downtime/year
- 99.99% (four nines) uptime = 52.60 minutes downtime/year
- 99.999% (five nines) uptime = 5.26 minutes downtime/year
Here is an availability table with nines up to 10, including pronunciations:
| Nines | Pronunciation | % Uptime | Downtime per year |
|---|---|---|---|
| 1 | One Nine | 90% | 36.5 days |
| 2 | Two Nines | 99% | 3.65 days |
| 3 | Three Nines | 99.9% | 8.76 hours |
| 4 | Four Nines | 99.99% | 52.56 minutes |
| 5 | Five Nines | 99.999% | 5.26 minutes |
| 6 | Six Nines | 99.9999% | 31.56 seconds |
| 7 | Seven Nines | 99.99999% | 3.16 seconds |
| 8 | Eight Nines | 99.999999% | 315.58 milliseconds |
| 9 | Nine Nines | 99.9999999% | 31.56 milliseconds |
| 10 | Ten Nines | 99.99999999% | 3.16 milliseconds |
Note: As the nines increase, the downtime reduces exponentially. Five nines (99.999%) are common for mission-critical systems. Nine nines (99.9999999%) represent the highest availability realistically achievable, with downtime of just 31.56 milliseconds annually. Measuring availability in nines provides an intuitive scale for benchmarking system uptime.
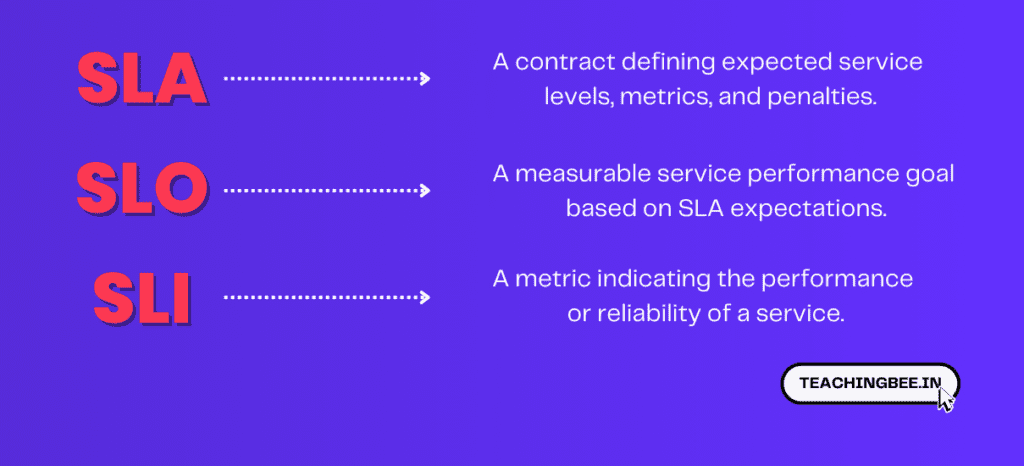
SLAs, SLOs, and SLIs
SLAs, SLOs, and SLIs are important concepts in the world of service-level management and reliability engineering. They are often used to define, measure, and manage the performance and reliability of services and systems. Here’s what each of these terms means.
- SLA (Service Level Agreement): An SLA is a formal contract or agreement between a service provider and its customers that outlines the expected level of service, including performance metrics, responsibilities, and penalties for non-compliance.
- SLO (Service Level Objective): An SLO is a specific, measurable target or goal set by a service provider that defines the level of service reliability and performance they aim to deliver to their customers. SLOs are typically based on the expectations outlined in SLAs.
- SLI (Service Level Indicator): An SLI is a quantifiable metric or measurement that reflects the performance or reliability of a service. SLIs are used as the basis for evaluating whether SLOs are being met.
To put these concepts into context, let’s use an example:
Imagine you are the provider of a cloud storage service, and you want to define SLAs, SLOs, and SLIs for your service:
- SLA: You agree to provide 99.9% availability for your cloud storage service to your customers.
- SLI: You measure the availability of your cloud storage service using the percentage of successful requests in a given time frame, e.g., 99.9% successful requests in a month.
- SLO: Your SLO is to maintain a 99.9% availability for your cloud storage service over one month. This means you commit to achieving this level of service reliability.
| Metric | SLA | SLO | SLI |
|---|---|---|---|
| Definition | Formal agreement between provider and customer specifying service levels | Specific measurable targets set by provider to achieve service levels | Metrics and mechanisms used to evaluate if SLOs are satisfied |
| Scope | Broad, covers overall service quality and responsibilities | Narrow, focused on quantitative service metrics and dimensions | Low-level performance indicators tied to SLOs |
| Focus | Service quality requirements for customer | Internal service quality targets for operations | Technical measurement of SLOs |
| Metrics | Uptime, response time, data accuracy specified | Uptime %, latency, error rate, throughput set | Monitoring systems, log data, probes used |
| Purpose | Establish service levels customers can expect | Break SLA into measurable internal goals | Track if SLOs are being met |
| View | External facing to customers | Internal facing within organization | Internal operational observability |
| Outcome | Legal basis for service quality compliance | Guide to achieving service commitments | Insights into achieving SLOs |
In summary, SLAs represent business needs, SLOs represent engineering targets, and SLIs provide monitoring and reporting.
How do we achieve High Availability in System Design?
5 ways to improve system availability are:
- Build Redundancy: Building redundancy means having backup or duplicate components in your system so that if one fails, another can take over seamlessly.
- Example: In a highly available web service, you have multiple identical servers. If one server crashes, the others continue to handle user requests, ensuring uninterrupted service.
- Automate Failovers: Automating failovers involves setting up processes or scripts that can automatically detect failures and switch to backup components without manual intervention.
- Example: In a highly available database system, if the primary database server becomes unresponsive, automated scripts can reroute database traffic to a secondary server, ensuring continuous access to data.
- Fault Isolation: Fault isolation means designing your system in a way that problems or failures in one part of the system do not impact the entire system.
- Example: In a highly available network, if one network switch experiences issues, it doesn’t disrupt the entire network because switches are isolated from each other.
- Monitor Closely: Monitoring closely involves continuously tracking the performance and health of system components, looking for signs of trouble.
- Example: In a highly available cloud service, monitoring tools constantly check server performance, and if they detect excessive CPU usage or network bottlenecks, they send alerts for immediate attention.
- Test Disaster Recovery: Testing disaster recovery means regularly simulating extreme scenarios (like data center failures) to ensure that your system can recover and continue functioning under the worst-case conditions.
- Example: In a high-availability data storage system, you periodically conduct tests where you intentionally disconnect a data center and verify that data replication and failover mechanisms successfully maintain data integrity and service availability.
Above practices like redundancy, automation, isolation, monitoring, and testing best practices comprehensively can help maximize system availability and achieve high uptime.
Availability Patterns In System Design
To incorporate the above solutions there are some of the Availability patterns to ensure high availability of distributed System. Some of which are:
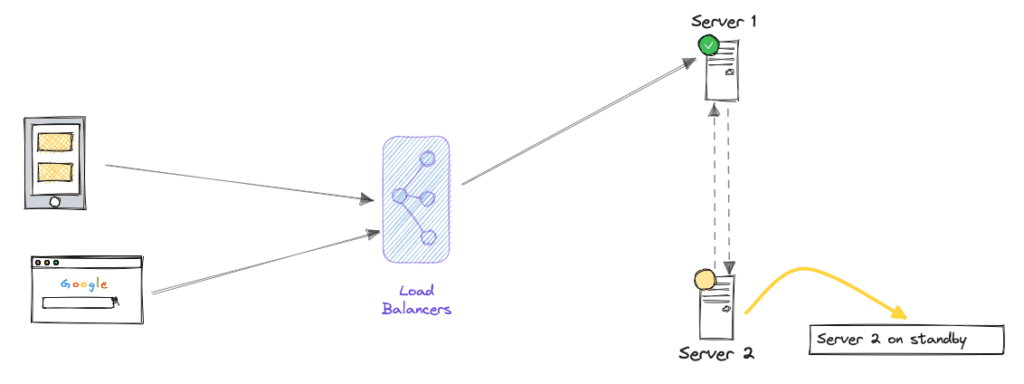
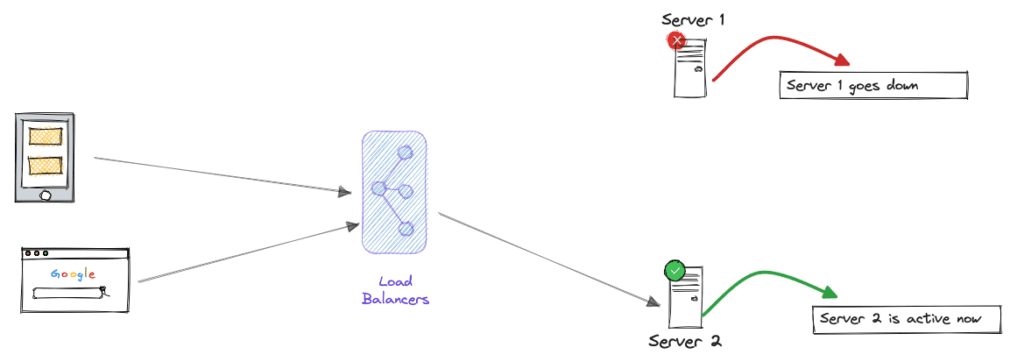
- Failover Patterns: Failover patterns focus on maintaining system availability by automatically switching to a redundant or standby component when the primary one fails. There are two main types of failover patterns:
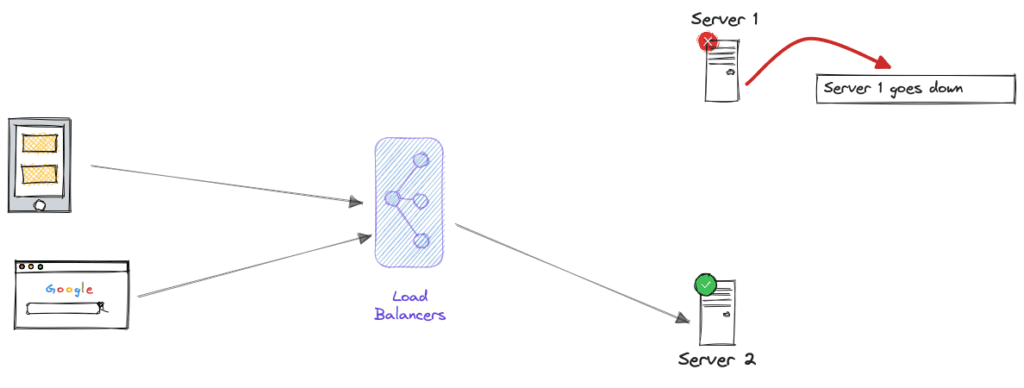
- Active-Passive Failover: In an active-passive failover, one component (the active one) serves traffic while the other (the passive one) remains idle. If the active component fails, the passive one takes over. For Example A web server cluster with one active and one passive server. If the active server fails, the passive server becomes active to handle incoming requests.
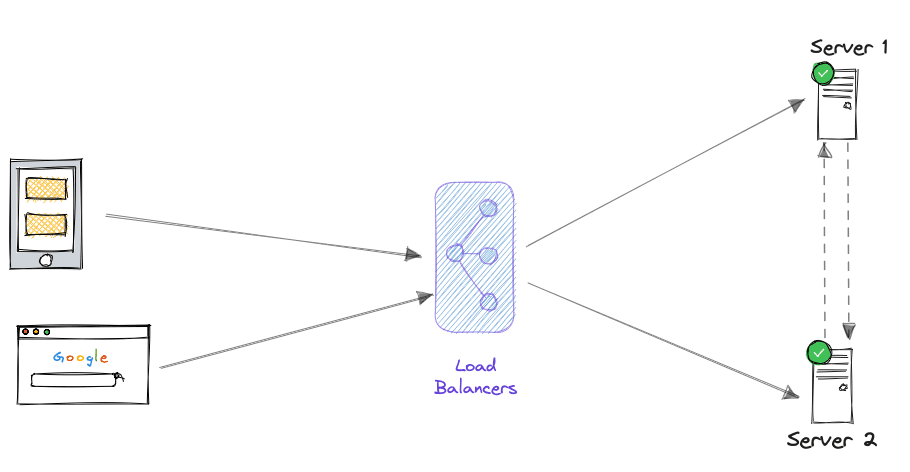
- Active-Active Failover: In an active-active failover, both components are actively serving traffic simultaneously. If one fails, the other(s) can still handle the load. For Example: Content delivery networks (CDNs) employ active-active failover, with multiple data centers serving content concurrently. If one data center experiences issues, the others continue to provide content.
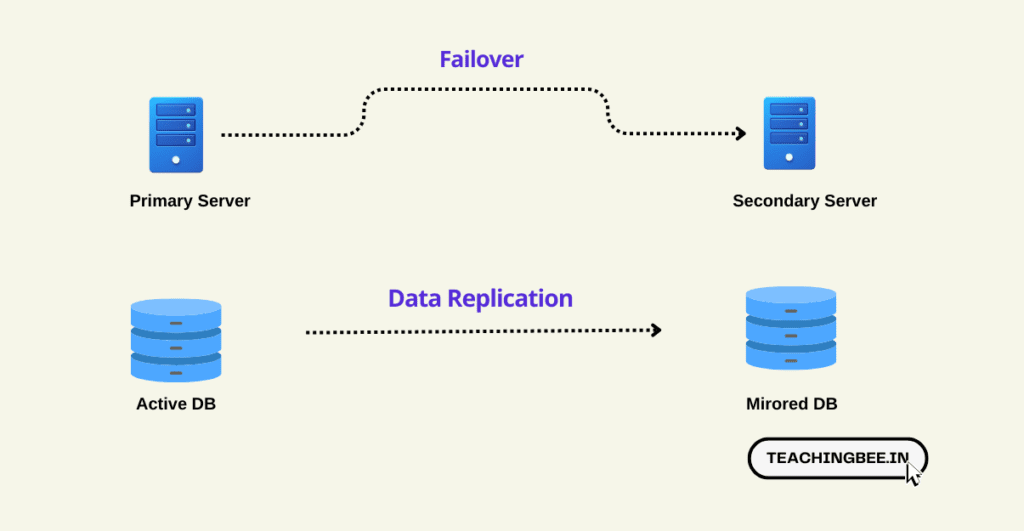
- Replication Pattern: Replication patterns ensure data availability by duplicating critical data across multiple servers or locations. There are various replication types:
- Master-Slave Replication: In this setup, one database server (master) handles write operations, while one or more other servers (slaves) replicate data from the master for read operations. For Example: MySQL databases can use master-slave replication for scalability and redundancy.
- Multi-Master Replication: In multi-master replication, multiple servers can both read from and write to the database. Changes made on one server are propagated to others. For Example: Distributed NoSQL databases like Cassandra implement multi-master replication for high availability.
- Degradation Pattern: The degradation pattern involves gracefully reducing non-critical functionality during failures to prioritize core functionality and maintain user experience. For Example: During high-traffic periods, an e-commerce website may disable advanced features like product recommendations to ensure that basic functions like browsing and purchasing remain responsive.
- Retry Pattern: The retry pattern automatically retries failed operations after a delay, allowing the system to recover from transient failures. For Example: An email service may retry sending an undelivered email a few times with increasing intervals between attempts before considering it permanently undeliverable.
- Timeout/Circuit Breaker Pattern: This pattern sets time limits for responses and fails fast if the response doesn’t arrive within the specified time. For Example, An API client may set a timeout of 5 seconds for a request. If the API doesn’t respond within this time frame, the client takes corrective action, such as notifying the user or trying an alternative.
- Redundant Storage Pattern: Redundant storage duplicates data across multiple disks or storage devices to tolerate hardware failures. For Example: In enterprise servers, RAID configurations (e.g., RAID 1, RAID 5) are used to ensure data availability and integrity even if a disk fails.
- Watchdog Pattern: In the watchdog pattern, an independent process continuously monitors the health of a system or its components and takes corrective actions if necessary. For Example: In a cloud-based infrastructure, a monitoring service like AWS CloudWatch can automatically scale resources up or down based on predefined health metrics to ensure system stability.
These availability patterns, including various types of failover patterns, are essential tools in designing resilient and highly available systems that can withstand different types of failures and disruptions.
Future Trends In High availability and System Design
Key potential future trends in high availability and system design:
- Increased use of microservices architecture – Breaking monolithic applications into independently scalable microservices can isolate failures and improve availability. But it requires availability at the service level.
- Serverless architectures – Using serverless platforms like AWS Lambda removes the need to manage servers entirely and provides intrinsic scalability and availability. But it requires rethinking stateless function design.
- Automated failover and healing – Automation will help improve the speed and reliability of failingover across availability zones or regions. Self-healing systems that auto-detect and recover from failures will become more common.
Key Take Aways
To Summarize :
- Availability refers to the percentage of time a system remains functional and operational. It measures uptime and resilience.
- High availability is crucial for distributed systems to ensure fault tolerance, meet SLAs, minimize revenue loss, and reduce disruptions.
- Availability is measured using percentage uptime or number of nines (9s) representing annual downtime. 5 nines (99.999%) is a common target.
- SLAs define service levels for customers, SLOs set internal targets, and SLIs track if SLOs are met.
- Redundancy, automation, isolation, monitoring, and disaster recovery testing help improve availability.
- Common availability patterns are failover, replication, degradation, retry, circuit breaker, redundant storage, and watchdog.
- Future trends will involve increased use of microservices, serverless, automation, edge computing, AI-assisted management, declarative infrastructure, holistic monitoring, and chaos engineering.
FAQ
What happens if you achieve 100% availability?
Answer: 100% availability is theoretically impossible for any complex, distributed IT system. Even aiming for extremely high availability like 99.999% uptime comes with diminishing returns and high costs.
How does geographic redundancy improve availability?
Answer: Distributing infrastructure and traffic across different geographic regions helps minimize downtime from localized failures or disasters. If one region goes down, others remain available.
Can you have too much redundancy?
Answer: Yes, excessive redundancy can increase costs and complexity beyond the benefits. The trick is finding the right level of redundancy for business needs without overengineering.
How do you test and measure availability?
Answer: Common practices include load testing, chaos engineering (injecting failures), monitoring uptime, and tracking service metrics. SLAs and SLOs provide measurable targets.
Will we ever achieve fault-tolerant systems?
Answer: True fault tolerance is hard to achieve given infinite points of failure. The goal is to design resilient systems that anticipate failures and recover quickly with minimal disruption.


