

In the era of cloud computing and globally distributed applications, delivering a seamless user experience is more complicated than ever. Why? Distributing components across networks, servers, and data centres introduces inconsistency risks.
Users who interact with a system expect uniform, predictable results no matter which server handles the request. But out-of-sync distributed elements can produce anomalies, errors, and data corruption. Consistency is the hidden force that coordinates components to avoid such chaos.
Consider consistency as the invisible glue binding together the scattered pieces of distributed systems. This glue ensures components have matching states, execute operations correctly, and produce expected results. Without it, distributed systems would devolve into buggy, unusable messes.
What Is Consistency In System Design ?
Consistency means that all system parts behave in a predictable, standard way, even when spread across different servers, services, or locations. Consistent systems guarantee to produce the same expected outcomes, regardless of where the requests are processed. There is uniformity and coherence in how distributed components interact within the overall system.
Consistency is critical in system design to ensure components behave predictably despite distribution. For example,
- An online shopping website has many servers. When a user adds an item to their cart, that update must show up properly, no matter which server handles their subsequent request. The cart cannot lose things due to inconsistency.
- Similarly, When transferring money online between bank accounts, deducting funds from one account and adding them to another must occur transactionally. If the system only deducts from account A but fails to credit account B due to consistency, money is lost or duplicated correctly. Consistency ensures both accounts are updated atomically.
At a high level, all system components like the website, databases, and caches must use data and logic in the same consistent way. They cannot have different incorrect versions that lead to inconsistent data.
Why Is Consistency In Design Important?
Consistency in system design is crucial for building reliable, usable, real-world systems. When components are distributed across locations, servers, and networks, inconsistent behaviours and anomalies can occur if elements operate out of sync.
Here are three different crucial examples that illustrate the importance of consistency in system design:
Online Banking Transfers
When transferring money between accounts in a banking system, read/write consistency ensures the correct balance is maintained in each account. When User A sends money to User B, read/write consistency ensures:
- User B’s balance was updated to show the received money first.
- Any future checks of User A’s balance will display a reduced amount.
- The transfer is handled atomically – both accounts are updated consistently, not just one.
This synchronization ensures deducted funds are added; account balances reflect transfers, and overall data remains consistent. With it, transfers could correctly debit with crediting or double-count funds. Read/write consistency coordinates distributed data updates to maintain the correctness of operations like bank account transfers.
E-commerce Checkout
During checkout on an e-commerce website, a customer’s cart items, pricing, selected shipping address, and payment method must remain consistent as requests span web servers. Inconsistent views of the cart state could remove items randomly or charge incorrect amounts. Consistent coordination ensures correct checkout behaviour.
Multi-Region DNS Routing
A DNS service with worldwide regions must consistently return the same IP address for a domain name across users. Inconsistent DNS responses could route users to different data centres, providing inconsistent web or app experiences. DNS consistency directs traffic appropriately.
In all the above cases, lack of consistency introduces incorrect system state and behaviour. For real-world scenarios like financial transactions, purchases, and network routing, consistent coordination across distributed components is essential for correct functioning.
Types Of Consistency In Distributed Systems: Consistency Patterns
There are several types of consistency patterns that can be employed to ensure that distributed data remains accurate and reliable across multiple nodes or components. Here are some common consistency patterns:
Strong Consistency
Every read retrieves the most recent write in a strongly consistent system. This creates the illusion that operations occur sequentially and instantly, even if they span multiple nodes. Strong consistency provides linearizability guarantee and coordination between nodes. Thus, in strong consistency
- All nodes reflect the latest write – no stale data.
- All operations appear to execute atomically and in order.
- Transactions maintain ACID properties.
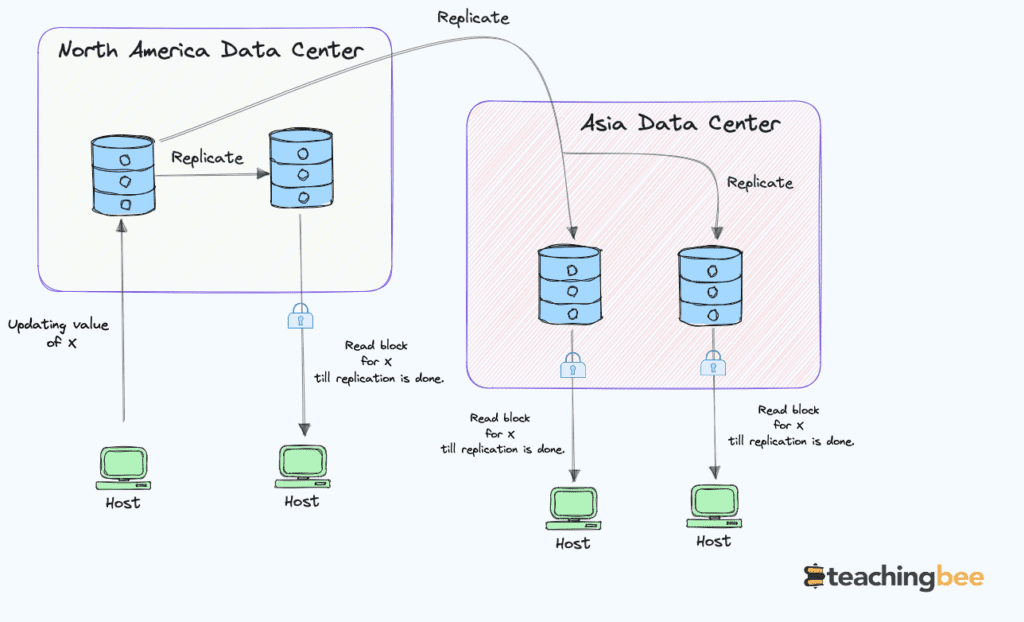
Examples
Consider a real-time stock trading platform. When a trader executes a buy order for 100 shares, the system must immediately deduct those shares from the available inventory. If another trader attempts to purchase the same shares at precisely the same moment, they should see that only 900 remain available now, not the original 1000. Any discrepancy or delay in reflecting the updated inventory could result in financial loss, failed trades, or other issues.
Techniques To Enforce Strong Consistency
- Atomic transactions: Atomic transactions with ACID properties are database transactions that ensure atomicity, consistency, isolation, and durability principles. It is executed in an all-or-nothing manner, preventing invalid or partial operations.
- Pessimistic locking: When a node retrieves a resource for reading or updating, it acquires a lock that prevents other nodes from modifying it simultaneously. This prevents dirty reads and lost updates.
The Downside Of Strong Consistency
The coordination required to provide linearizable operations can reduce availability. If nodes cannot agree on state changes, operations may stall or fail. This impacts efficiency and responsiveness.
When To Use Strong Consistency
For cases where up-to-date data is critical, like financial systems, multiplayer games, or real-time collaboration tools. The correctness of outcomes usually takes priority over performance.
Weak Consistency
Weak consistency prioritizes availability and partition tolerance over consistent reads and writes. It allows nodes to return stale data for a while even after an update. Thus, in weak consistency
- Nodes can read stale data that does not reflect the latest writes.
- Updates propagate asynchronously through the system.
- Transactions have reduced isolation guarantees.
Weak consistency relaxes the data accuracy, and transaction isolation guarantees strong consistency to improve availability and performance.
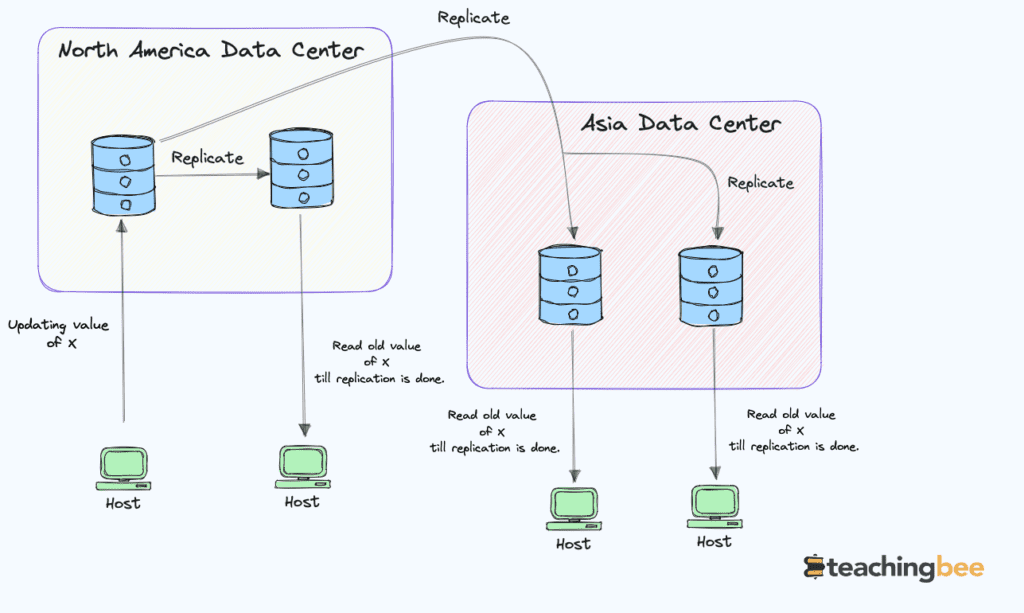
Examples
- DNS (Domain Name System): When the IP address for a domain name changes, DNS servers will still reflect the old address for a period known as the time-to-live (TTL). This allows the update to propagate through the network of DNS servers gradually. During this time, some clients will be directed to the old IP.
- Email: After an email is sent, there is typically a delay before it appears in the recipient’s inbox. As the email transfers between mail servers, each server takes time to process and forward it. The recipient may also check for new mail periodically rather than continuously.
Types Of Weak Consistency
Different types of Weak Consistency are:
Eventual Consistency
Eventual consistency is a weak consistency model used in distributed systems that guarantees data will eventually become consistent across nodes, but allows for periods of inconsistency. This means updates propagate to all nodes over time, however, there may be gaps where some nodes have the latest data while others need to be updated. Thus, in the Eventual Consistency Consistency Model
- Data replicas across nodes can temporarily differ
- Updates are propagated asynchronously between replicas
- Inconsistencies are typically resolved within milliseconds or seconds
With eventual consistency, an update may only be instantly reflected on some nodes. However, over time, given a period of no new updates, all replicas will converge to the same state. DNS and email follow eventual consistency. For instance, when you save a photo to a cloud storage platform from your phone, you might not immediately see it if you access it from your computer.
Read Your Writes
Read your writes consistency ensures that after a node performs a write, subsequent reads on that node will always reflect that write but doesn’t guarantee updated data from other nodes immediately. This means In the Read Your Writes Consistency Model
- Writes are immediately visible locally
- There is no guarantee that writes are immediately visible globally
- It Provides session consistency per node
They are used in collaborative tools and forums. Consider a forum. After you post a thread, you can instantly view it. However, a friend in another country might experience a delay before seeing your post.
Implementation
Caching, asynchronous replication, and looser transaction isolation levels provide weak consistency. Stale data is usually updated in the background or on subsequent access.
When to use Weak Consistency
For systems where occasional stale reads are acceptable to improve performance, availability, and network tolerance. They are used in caching systems, cloud storage, and collaborative tools.
Downsides Of Weak Consistency
Stale data can cause unexpected application behaviour. Difficult to reason about concurrency and ordering of operations.
Causal Consistency
Causal consistency is a consistency model for distributed systems that preserves the partial ordering of related events caused by each node’s operations while allowing for the asynchronous and non-serialized execution of unrelated events.
The fundamental principles of causal consistency are:
- Causal Ordering: If event A causally precedes event B, all nodes will see A occur before B, even if the events originate from different nodes. Causal ordering prevents causality violations.
- Concurrency Allowed: Events that do not have a causal relationship may be seen in different orders on different nodes. Unrelated events can occur with relaxed synchronization between nodes.
Examples
In a collaborative document editor, if User A adds a title and User B adds a subtitle, all users will see the title inserted before the subtitle. However, two concurrent but unrelated edits may appear in a different order on different nodes.
Techniques To Enforce Causal Ordering
- Lamport timestamps: Each node maintains a counter indicating its logical clock time. Timestamps are attached to operations and used to order concurrent events.
- Version vectors: Vector clocks with an entry for each node are used to track causal dependencies between operations.
Benefits Of Casual Consistency Over Strong Consistency
- Only enforce ordering between causally related operations. Unrelated operations can occur with loose synchronization for better performance.
- Avoids coordination overhead of strong consistency models like serializability.
Benefits Of Casual Consistency Over Weak Consistency:**
- Provides deterministic ordering guarantees for related events.
- Prevents causality violations like seeing an effect before its cause.
When to use Casual Consistency
Distributed databases need coordinated reads and writes for related data items but allow flexibility for unrelated items. Useful for collaboration and synchronization.
Limitations
- Hard to reason about correctness and debugging.
- Timestamps and vector clocks have storage overhead.
- No guarantees provided for non-causally related operations.
Causal consistency relaxes the isolation of strong consistency when possible while maintaining application-meaningful ordering guarantees. Causal consistency improves performance while providing causal data accuracy.
Why not use Strict consistency all the time?
There are a few key reasons why strict consistency is not used all the time in distributed systems:
- Performance – Enforcing strict consistency requires high synchronization and node coordination. Strict consistency introduces latency and reduces throughput. For read/write heavy systems, the coordination overhead can significantly degrade performance.
- Availability – Strict consistency protocols block operations until data is synchronized across nodes. If any node fails or becomes disconnected, the system may become unavailable until consistency can be re-established. This lack of fault tolerance is problematic for large-scale distributed systems.
- Scalability – As the system grows in size and geography, the latency to coordinate and synchronize makes strict consistency challenging to maintain. The coordination overhead limits how much a system can scale while providing linearizable operations.
- Complexity – The logic required for each node to participate in strict consistency protocols can be quite complex. This makes application development more difficult.
- Cost – The redundancy, low-latency connectivity, and coordination logic required for strict consistency are expensive to implement and maintain at scale.
For these reasons, weaker consistency models that relax synchronization guarantees are often preferred. Applications will often favour availability, performance, and partition tolerance over consistency. However, strict consistency is still used when correctness relies on linearizable operations, like financial transactions. The tradeoffs depend heavily on the use case and requirements of the system.
Consistency Tradeoffs In Modern Distributed Database System Design
Some fundamental consistency tradeoffs in modern distributed database systems are:
Strong vs Eventual Consistency
- Strong consistency ensures all reads return the most recent write. Strong consistency requires synchronous coordination before completing reads and writes to ensure nodes have up-to-date data.
- Eventual consistency allows reads to return stale data, propagating updates asynchronously. Eventual consistency provides higher availability and performance.
- Strong consistency is necessary for use cases like financial transactions. Eventual is often preferred for global scale and high throughput.
- Hybrid models can use quorum techniques to provide strong and eventual modes.
Synchronous vs Asynchronous Replication
- Synchronous replication propagates writes to replicas before acknowledging the write. Synchronous replication ensures replicas are up-to-date but increases write latency.
- Asynchronous allows the source to complete writes without waiting for replicas. Asynchronous replication provides lower latency but allows replicas to lag.
- Asynchronous is preferred when availability and performance are critical. Synchronous is used when up-to-date replicas are required.
- A hybrid approach replicates synchronously to only a subset of replicas. The rest propagate changes asynchronously.
Linearizability vs Sequential Consistency
- Linearizability provides a stronger ordering guarantee, making operations appear atomic and in sequence globally.
- Sequential consistency only orders operations within a session, allowing more flexible concurrency.
- Linearizability simplifies reasoning but has a higher cost. Sequential consistency is generally preferred today.
Isolation Levels
- Weaker isolation levels like read committed increase concurrency but create risks like dirty reads.
- Stronger isolation, like serializable, prevents anomalies but restricts concurrency.
- Allowing applications to pick their isolation level is a common approach.
There are many tunable tradeoffs around consistency, concurrency, and coordination. Hybrid and configurable models provide the best combination of strong and eventual properties.
Key Take Aways
To conclude and summarise:
- Consistency coordinates the moving parts of distributed systems to act as one unified whole. Consistency
- prevents unexpected errors from popping up.
- Strong consistency emphasizes always reading the latest version of data. Eventual consistency allows temporary inconsistency but converges over time.
- There are fundamental tradeoffs between strong consistency and high availability during network partitions. Consistency models impact performance.
- Causal consistency preserves the partial order of events without total synchronization. Hybrid models blend strong and weak consistency.
- Modern databases offer many knobs to fine-tune consistency guarantees versus performance needs. Consistency requirements depend on the use case.
I hope You liked the post ?. For more such posts, ? subscribe to our newsletter. Do check out more concepts like availability in system design.
FAQ
What are the benefits and downsides of strong consistency?
Answer: Strong consistency provides linearizability, synchronized state changes, and transactions with ACID properties. Strong consistency prevents anomalies and ensures correct operation. However, it incurs high coordination overhead that limits performance, availability, and scalability.
How does causal consistency differ from sequential consistency?
Answer: Causal consistency preserves the partial order of causally related events while allowing unrelated events to be unordered. Sequential consistency only guarantees the order of operations within a session but not globally between sessions.
What tuning options do modern databases provide for consistency?
Answer: Modern distributed databases offer many options like quorum configurations, synchronous/asynchronous replication, hinted handoff, conflict resolution logic, and per-operation consistency selection. These levers allow tailoring consistency guarantees to specific application requirements.


