
CAP theorem is a fundamental concept in the world of distributed systems. In this article we will understand the CAP theorem in dbms with examples, its implications for system design, and how popular databases make CAP trade-offs.So, Let’s get started.
What is CAP Theorem?
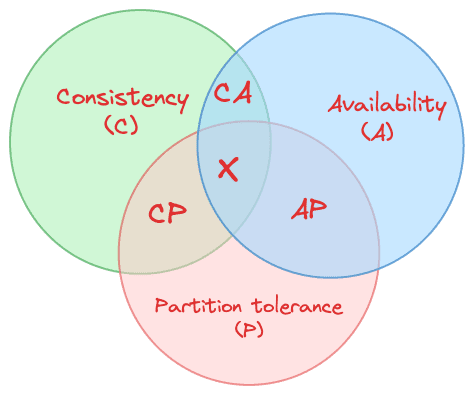
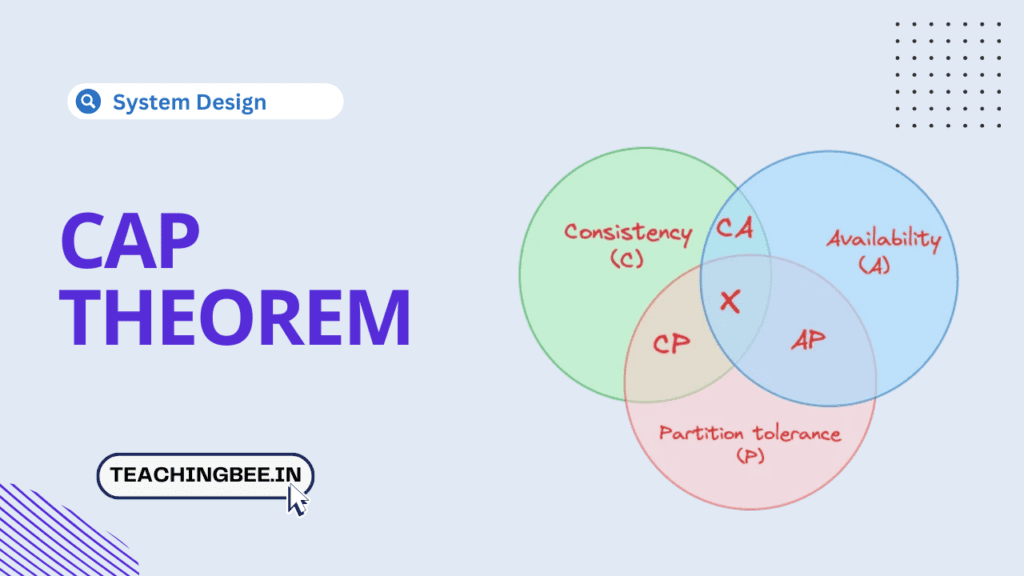
The CAP theorem, also known as Brewer’s theorem, states that it is impossible for a distributed data system to provide more than two of the following three guarantees simultaneously:
- Consistency (C)
- Availability (A)
- Partition tolerance (P)
Before, going into the details, let’s first understand the terms associated with the CAP Theorem
Understanding C, A, and P
- Consistency (C) – This ensures every client has the same view of the data. Consistency is achieved by updating all the replicas with the most recent write before allowing further reads. So, every read from the data store will return the most recent write. All clients will have a consistent view of the data. To know more in detail checkout our previous post.
- Availability (A) – This ensures every request is responded to, even if the response contains stale data. The system guarantees availability even in cases of network failures or partitions. Availability is achieved by allowing reads and writes on any replica. To know more in detail checkout our previous post.
- Partition tolerance (P) – This refers to the ability of a distributed system to continue operating correctly even when network partitions (i.e., communication breakdowns between nodes in the system) occur.
Now, Let’s understand the CAP theorem via example:
Understanding CAP Theorem With Example
Consider a distributed database with nodes A, B, and C replicated across 3 data centers. If the network connection between A and B fails:
- The system can maintain consistency by locking out C until A and B can synchronize. This reduces availability as one node is locked out.
- The system can maintain availability by allowing C to continue reading and writing. This reduces consistency across A, B, and C, as all three nodes will not have the most recent data.
- The system can maintain partition tolerance by remaining operational with guaranteed consistency and availability within partitions A and B+C, respectively.
So, according to the CAP theorem, the system cannot have all C, A, and P in this partition scenario. At most, two can be guaranteed simultaneously. So, In the event of a network partition in a distributed system, there is a trade-off between consistency and availability. The system designer has to make a software architecture choice to favour either consistency or availability while still maintaining partition tolerance.
In summary, the CAP theorem states that a distributed system cannot simultaneously ensure strong consistency, availability, and partition tolerance. At most, two can be guaranteed due to the inherent trade-offs when a network partition occurs.
Categories Of System Based On CAP Theorem Trade-Offs
Based on the trade-offs the CAP theorem provides, the system can be divided into three categories.
CP (Consistency and Partition Tolerance):
- A CP system prioritizes data consistency and partition tolerance over availability.
- In a CP system, the data in the distributed nodes remains consistent, even when network partitions occur between the nodes.
- The downside is that during a network partition, the system chooses to sacrifice availability. Some nodes may be unable to process requests to maintain data consistency across all nodes.
- Examples include distributed databases like MongoDB . It uses replication and quorum-based mechanisms to enforce strong data consistency across nodes.
AP (Availability and Partition Tolerance):
- AP Systems favour availability and partition tolerance over consistency.
- AP systems remain highly available for client requests, even when network partitions occur between nodes.
- However, since the isolated nodes can continue accepting writes independently, the overall distributed data can become inconsistent during a partition.
- AP systems focus on availability and accept that the data may not be consistent all the time.
- Examples Apache Cassandra which uses hinted handoff to guarantee availability.
CA (Consistency and Availability):
- CA Systems favour consistency and availability over partition tolerance.
- In a CA system, every request receives a valid response, without delays or failures, as long as the distributed nodes remain connected.
- Consistency is maintained as all nodes see the same data simultaneously.
- However, if a network partition occurs between nodes, the guarantees of CA are lost – the system can either stop responding/processing requests or become inconsistent.
- Examples are traditional databases like Oracle and MySQL, which use synchronous replication. As long as the nodes can communicate, strong consistency is maintained through atomic transactions and total data replication.
Importance of CAP Theorem In System Design
The CAP theorem is essential when designing distributed systems because it highlights the inherent trade-offs between consistency, availability, and partition tolerance. Here are some key reasons why the CAP theorem is essential in system design:
- It helps set the right expectations – There is no “one size fits all” system that can guarantee CA, CP, and AP together. Based on requirements, designers have to pick 2 out of the 3 CAP properties.
- Drives architecture decisions – Whether to opt for a CP, AP, or CA system has architectural implications. CP systems favor consensus-based approaches. AP systems require reconciliation mechanisms. CA systems need tight synchronization.
- Informs trade-off discussions – CAP theorem provides a framework to discuss the system trade-offs with stakeholders. Based on their priorities between C, A, and P, appropriate technical choices can be made.
- Promotes system awareness – CAP theorem makes engineers aware of distributed systems properties during failures. It highlights that failures will happen and trade-offs are inevitable.
- Focuses on business needs – By tying CAP properties to business requirements, the CAP theorem encourages system designs that directly serve business objectives.
- Enables loose coupling – Knowing that distributed systems have to sacrifice one CAP property helps teams build loosely coupled components that fail gracefully.
CAP Theorem In NoSQL Databases
NoSQL databases make different trade-offs between CAP based on their architecture and use cases. Let’s see how popular NoSql databases like MongoDB and Cassandra uses CAP theorem.
CAP Theorem NoSQL Database Examples
MongoDB: A Focus on Consistency and Partition Tolerance
Let’s understand how CAP theorem in MongoDB is used. MongoDB is CP System, let’s understand how?.
Design
MongoDB’s design leans towards strong consistency and partition tolerance. The choice of CP means that in specific scenarios where network partitions occur, MongoDB may sacrifice availability to ensure that data remains consistent throughout the system.
Replication
MongoDB uses a replica set model to create multiple copies of the data. Each replica set has one primary node responsible for all write operations and multiple secondary nodes replicating the primary dataset. This replication enhances data durability and availability under normal circumstances.
Quorum-based Reads/Writes:
By using a quorum system for reads and writes, MongoDB ensures that data operations reflect the most up-to-date and consistent data. For writes, the primary node needs to acknowledge the operation, while for reads, depending on the read concern level, data can be fetched from primary or secondary based on how fresh and consistent the client wants the data to be.
Handling Failures
If the primary node fails or becomes unreachable, one of the secondary nodes is elected to be the new primary. However, once this election process is complete, write operations are only accepted, ensuring consistent data is introduced during this period. This emphasizes MongoDB’s inclination towards consistency over immediate availability.
Raft Consensus Protocol
MongoDB’s replication protocol is based on the Raft consensus algorithm. In Raft, most nodes (the quorum) must agree on the state changes. This ensures that even if a few nodes face issues or become partitioned, the system continues to maintain data integrity and consistency as long as a majority is in agreement.
Read Operations:
When clients issue read operations, MongoDB allows specifying the desired consistency through read concerns. For instance, using a read concern of “majority” ensures the client gets data acknowledged by the majority of replica set members, guaranteeing more data consistency.
Trade-offs:
MongoDB’s emphasis on consistency and partition tolerance does come with a trade-off. In situations where a partition isolates a majority of the nodes or where an election process is ongoing, the system might not serve write requests, sacrificing availability for a short period. This is a conscious design choice, prioritizing data integrity and consistency.
In essence, MongoDB has been architectured with a strong inclination towards ensuring that data remains consistent across its distributed nodes, even if it means occasionally sacrificing immediate availability, especially during network partitions or node failures.
Cassandra: A Focus on Availability and Partition Tolerance
Let’s understand how CAP theorem in Cassandra is used. Cassandra is AP System, let’s understand how?.
Design
At its core, Cassandra is designed to ensure high availability and resilience to network partitions. It allows some data inconsistency across nodes, which is eventually reconciled.
Distributed Nature
Cassandra’s data distribution model is based on a ring architecture. Data is partitioned across multiple nodes, and each piece of data is replicated to multiple nodes to ensure fault tolerance.
Hinted Handoff
One of Cassandra’s mechanisms for ensuring high write availability is the ‘hinted handoff.’ If a node meant to receive a write is down or unreachable, another node temporarily stores the write. Once the original node becomes available, the data is handed off and replayed, ensuring data isn’t lost even if immediate writes to the intended node aren’t possible.
Proximity-Based Operations
To optimize performance and enhance availability, Cassandra can read or write data from the nearest nodes (considering network latency). While this increases availability and responsiveness, it can lead to temporary inconsistencies if the closest node has stale data.
Tunable Consistency Levels
One of Cassandra’s notable features is the ability to adjust the consistency level for each read-and-write operation. This means clients can specify how many replicas should acknowledge a read or write operation before it succeeds. For example, setting a higher consistency level (like QUORUM) demands more replicas to agree, leaning towards stronger consistency. A lower level (like ONE) prioritizes availability and speed but can result in reading stale data.
Eventual Consistency
Due to its emphasis on availability, Cassandra follows an ‘eventual consistency‘ model. This means that over time, once network partitions are resolved, data across nodes will converge and become consistent. However, during network disruptions or high latencies, data discrepancies can occur across nodes.
Trade-offs
By embracing the AP model, Cassandra guarantees that the system will always be available for reads and writes, even during network partitions. The trade-off is that it might occasionally serve outdated data. Depending on the use case, this might be acceptable, especially when the primary concern is maintaining a responsive and available system.
In conclusion, Cassandra’s architecture prioritizes ensuring that the database remains operational and responsive, especially in environments where network partitions are common. While it does introduce mechanisms to manage and reduce inconsistencies, it acknowledges and embraces the fact that temporary inconsistencies can exist, reflecting its commitment to availability and partition tolerance.
Key Takeaways
- CAP theorem states that distributed systems cannot guarantee Consistency, Availability, and Partition Tolerance. At most, two can be guaranteed.
- Based on CAP trade-offs, systems are categorized as CP (Consistency and Partition Tolerance), AP (Availability and Partition Tolerance), or CA (Consistency and Availability).
- CP systems like MongoDB sacrifice availability to maintain consistency during partitions. They use consensus protocols like Raft.
- AP systems like Cassandra sacrifice consistency for availability. They use mechanisms like hinted handoff and tunable consistency.
- CA systems lose CAP guarantees during partitions. They maintain consistency and availability when no partitions occur.
- CAP theorem has significant implications on distributed system design based on business needs.
Similar Posts
I hope You liked the post ?. For more such posts, ? subscribe to our newsletter. Try out our free resume checker service where our Industry Experts will help you by providing resume score based on the key criteria that recruiters and hiring managers are looking for.
FAQ
Does the CAP theorem apply to databases like SQL Server that run on a single server?
No, the CAP theorem applies only to distributed systems. Databases like SQL Server do not have to make CAP trade-offs as they are not distributed systems.
What is the difference between PACELC and CAP theorem?
PACELC is an extension of the CAP theorem. It introduces C and E consistency models during network partitions (P) and normal operations (E), respectively. CAP focuses on trade-offs during partitions.
Does PACELC replace the CAP theorem?
No, PACELC builds on the CAP theorem. It does not replace CAP but provides additional consistency models for normal vs partition scenarios. CAP continues to be a core distributed systems theorem.
What is the difference between CAP and ACID?
CAP applies to distributed systems, while ACID applies to database transactions. CAP discusses trade-offs between consistency, availability, and partition tolerance in distributed systems. ACID focuses on guaranteeing consistency, atomicity, isolation, and durability for database transactions.
Can a distributed database be both ACID and CAP compliant?
Yes, a distributed database can provide ACID guarantees for transactions within a single node or database instance. It can also make CAP trade-offs across multiple nodes in the distributed database system. The scopes are different.


