
Every growing digital service hits a moment where it can either break or shine because of too many users. Think of it like a city with too many cars, causing traffic jams. If planned correctly, the service can continue and run smoothly when everyone tries to use it simultaneously. But with the proper planning, more users can make the service better. This is called scalability.
Scalability in system design is like magic for these services. They can stretch and grow like a cloud instead of being trapped in a small box. Companies like Facebook and Uber use this magic to ensure they work well for millions of users worldwide. When done right, it’s like turning traffic jams into highways!
This guide will share the secrets of how these big companies make sure they don’t crash when they become popular. Learn these tricks, and your service will be ready to welcome even more users with open arms.
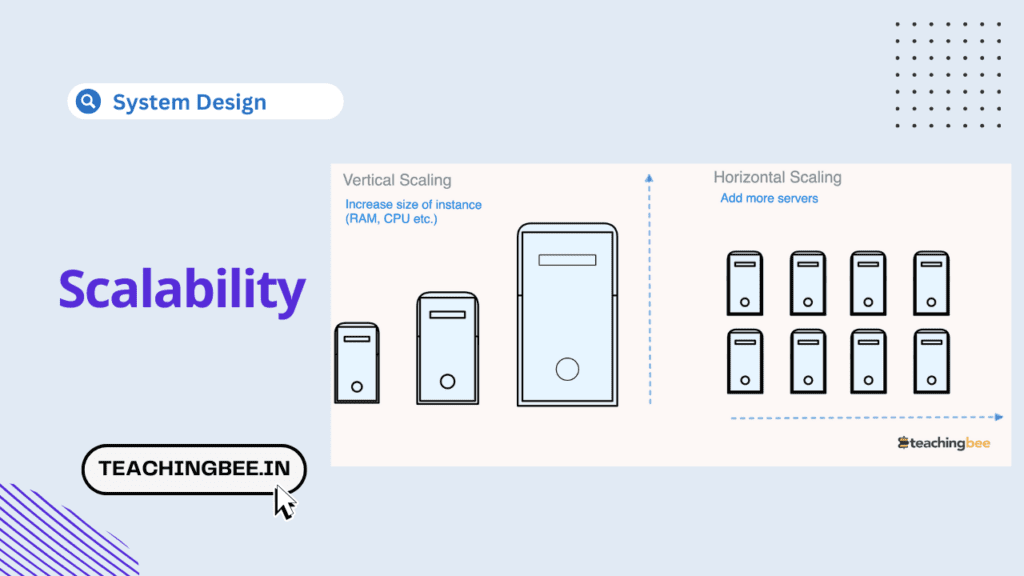
What does scalability mean?
Scalability in system design refers to a system’s capacity to manage an increasing workload seamlessly. Essentially, it’s the system’s adeptness to boost its performance when additional resources, such as servers, are incorporated. This ensures the system can efficiently adapt to heightened demands over time, ensuring optimal performance without succumbing to failures or incurring excessive costs.
In a technical context, “workload” might corresponds to increased computational demands, expanded data volumes, or a surge in incoming system requests.
Understanding Scalability Using Ride-Sharing Example
Imagine you start a ride-sharing service called “QuickRide” in a tiny town. At first, your app servers only need to handle a few hundred requests daily. As “QuickRide” expands to more cities, your user base grows exponentially, meaning your servers must handle millions of requests daily.
If “QuickRide” was designed to be scalable, it could handle this growth smoothly. As demand increases, you can add servers and cloud resources that automatically scale capacity. This ensures users still get fast, reliable service.
However, if “QuickRide” wasn’t made scalable, the surge in demand could overload the servers. This could cause slow response times, payment issues, and poor user experiences. Like a growing city might need to expand its roads and transit, a digital service like “QuickRide” needs to scale up its infrastructure to meet demand.
Making “QuickRide” scalable prepares it to handle future growth gracefully. This is key to ensuring excellent, uninterrupted service as the user base expands.
So, scalability allows a system to function correctly even as demand increases. This is done through the distribution of workloads, caching, database sharding, and horizontal scaling.
Importance Of Scalability In Software Design
Scalability is a crucial consideration in software design for several key reasons:
- Performance: A scalable system can maintain good performance even as load increases. With scalability, response times and latency will improve as traffic grows.
- Reliability: When demand surges, a system must remain stable and available. Scalability prevents overload conditions that can cause crashes or outages.
- Capacity planning: It’s impossible to predict future capacity needs accurately. A scalable design can adapt to usage spikes and growth over time.
- Cost efficiency: Scalable architectures can leverage lower-cost horizontal scaling approaches to minimize expensive hardware upgrades.
- Future-proofing: Systems that need to be more scalable often require major architecture overhauls to meet demand. Scalability means less re-engineering down the road.
- Customer experience: Users expect consistently good performance and availability. Lack of scalability leads to degraded experiences that frustrate customers.
- Time to market: Scale-out architectures allow new features and services to be launched more quickly without as much upfront infrastructure investment.
Building a scalable system from the start results in systems that can grow smoothly, remain stable under high loads, keep pleasing users, and avoid expensive re-work, critical ingredients for product success and business growth. Considering scalability early in development is far more accessible and cost-effective than bolting it later.
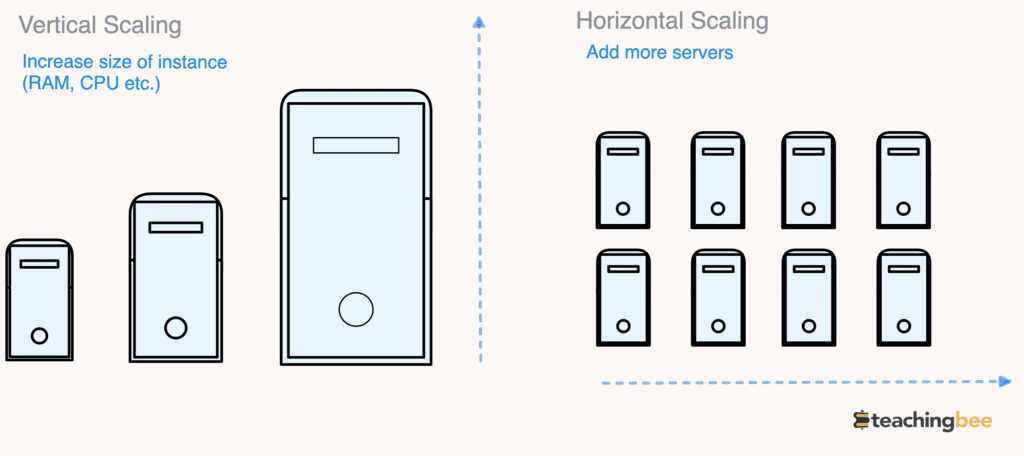
Types Of Scalability
Different types of scalability are:
Horizontal Scalability
Horizontal Scalability refers to scale-out, which involves adding more servers or instances to a distributed system to handle increasing workload.
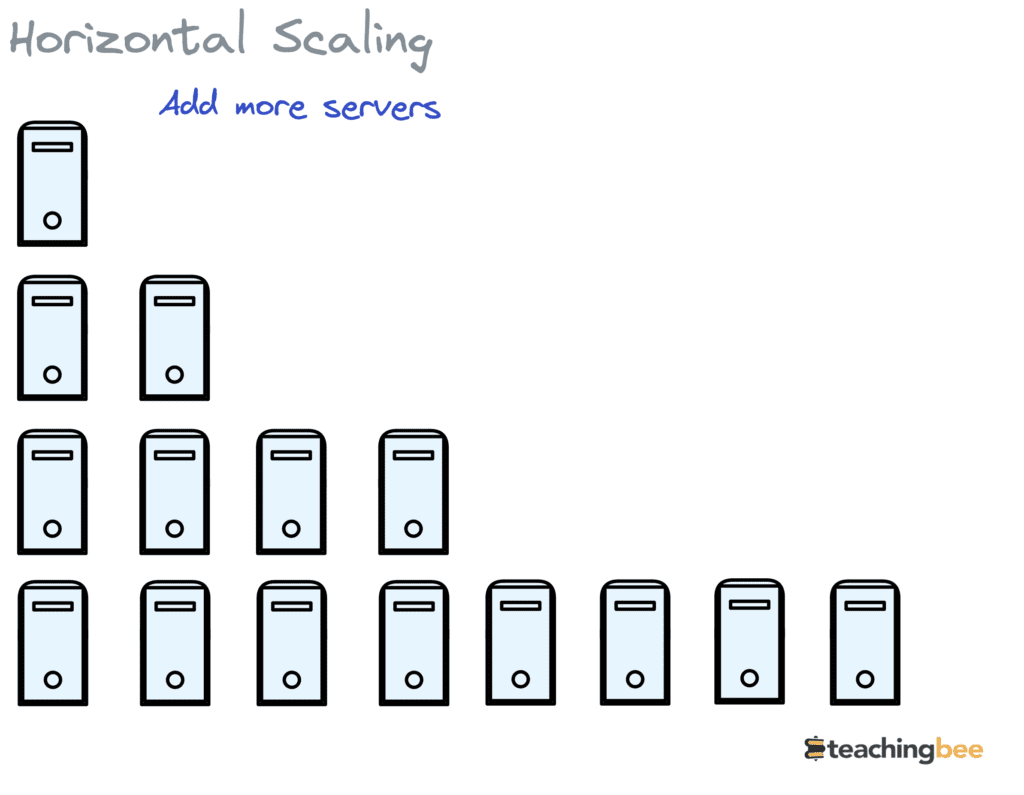
For example, suppose a company runs a mobile gaming app that is gaining popularity. Initially, the app’s backend services and databases run on just a few servers. As the number of active users and gameplay activity grows, horizontal scalability means deploying new servers and splitting up the processing and storage across these additional resources.
Different Ways To Implement Horizontal Scaling
- Load Balancers: Load balancers distribute incoming requests across the servers. Additional servers mean less load per server.
- Database Sharding: Database sharding partitions the data across multiple database instances on different servers. This parallelizes queries and transactions.
- Using Stateless Service: Stateless services allow requests to be handled independently by any server without requiring state synchronization.
- Containerisation and Microservices: Containers and microservices make it easy to launch identical app instances across the new infrastructure.
Horizontal scaling allows the system to incrementally expand capacity, reduce workload per server, and improve performance cost-effectively using commodity hardware. It is used by large distributed systems like Google and Amazon that require the ability to keep adding nodes seamlessly.
Benefits Of Horizontal Scaling
- Cost-effective – Adding commodity hardware is cheaper than upgrading to more powerful servers.
- Reliability – Distributed systems have no single point of failure. If one instance goes down, others can handle the work.
- Performance: Load can be distributed evenly across nodes. More nodes mean the ability to handle higher demand.
Vertical Scalability
This refers to scaling up by increasing the resources of an individual node, like upgrading to a more powerful server or increasing the specs of an existing server or resource within the system, like CPU, RAM, storage, or network bandwidth.
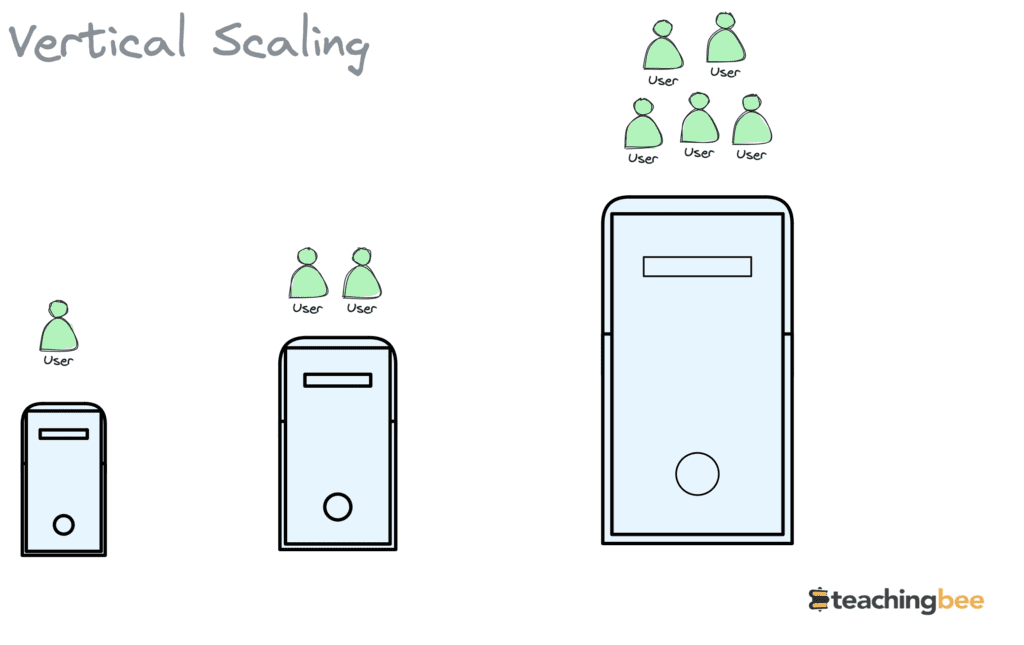
For example, imagine a company’s core database server is hitting capacity limits as data volumes grow. Vertically scaling this database could mean migrating it to a more powerful server with a faster processor, more cores, and higher memory capacity.
Different Ways To Implement Horizontal Scaling
- Moving to a server with a newer generation of CPU often doubles or triples performance.
- Increasing RAM allows more data to be cached and quickly accessed in memory.
- Adding storage improves I/O speeds and allows holding more data.
- Faster networking improves throughput between application layers.
Vertical scaling improves the performance and capacity of the specific component being upgraded. This is useful when the current specs of that resource constrain the system.
Benefits Of Vertical Scaling
- Simplicity: Expanding an existing node can be easier than distributing it across many nodes.
- Latency: Improved performance when tasks need fast interconnectivity or can’t be distributed.
When to use Horizontal Vs Vertical Scaling
Here are some general guidelines on when to use horizontal vs vertical scaling:
When To Use Horizontal Scaling
- When handling large volumes of traffic and workload distributed across multiple servers. Horizontal scaling improves performance by spreading out the load.
- For stateless services and compute resources that can operate independently without tight coupling between nodes. This allows the easy addition of cheap commodity servers.
- To improve reliability and uptime through redundancy across nodes. If one node fails, others can take over the workload.
- When future workload growth is unpredictable. Horizontal scaling allows flexible auto-scaling to match demand spikes.
- When you reach vertical scaling limits and cannot cost-effectively upgrade a single server any further.
When To Use Vertical Scaling
- When the workload is limited to a single process or component, like a database, that is the performance bottleneck. Upgrading this single node improves overall system performance.
- For large monolithic applications that cannot be easily distributed horizontally. There is a tight coupling between components.
- When the absolute lowest latency is needed. Bringing everything onto one powerful server provides fast interconnectivity.
- When the tech is rapidly improving. Upgrading to the latest servers with the newest hardware can provide significant performance boosts.
- When the operational overhead of managing many servers is high. Maintaining fewer, more powerful servers may be more straightforward.
In summary, horizontal scaling works well for distributed workloads and unpredictable growth, while vertical scaling helps when single-node performance and simplicity are essential. Many systems use a hybrid approach to get optimal results.
Principles and Best Practices for Designing Scalable Systems
- Decouple components – Tightly coupled systems are challenging to scale since expanding one component may require expanding the connected components simultaneously. Loose coupling allows components to scale independently as needed. For example, a loosely coupled web app may separate the frontend and backend APIs, caching layer, and databases into distinct services that can be scaled individually.
- Distribute bottlenecks – Identify potential bottleneck resources that could limit scaling, like databases or compute-heavy processes, and proactively distribute them. For instance, a distributed database like Cassandra spreads load across nodes through partitioning and replication. This allows linearly scaling capacity by adding commodity servers.
- Horizontal scaling first – Scale-out to more nodes before scaling up single nodes. Adding more low-cost instances improves cost efficiency and performance versus vertical scaling with expensive hardware upgrades. Horizontal scaling also provides high availability through redundancy.
- Automate scaling – Use auto-scaling tools offered by cloud platforms to automatically spin up or shut down resources based on measured load and performance metrics. This allows real-time response to usage spikes and minimizes manual overhead. For example, it is automatically adding app servers to meet traffic demands.
- Monitoring – Monitor and measure critical metrics like CPU usage, bandwidth, latency, and database load at scale. This reveals bottlenecks and spots provisioning issues before they become critical. Refine architecture as needed based on data-driven insights from monitoring production loads.
- Avoid single points of failure – Build redundancy at all layers so there are failover options if a component goes down.
How Can You Build Highly Scalable System?
Here are some fundamental scalability techniques and strategies to build highly scalable system:
- Load Balancing – Distributes network traffic and workload evenly across servers. Improves responsiveness and availability. Common approaches are round-robin, least connections, IP hashing, etc.
- Database Sharding – Splits and distributes data across multiple database instances residing on different servers. Enables horizontal scaling of the database.
- Caching – Stores frequently accessed data in memory for low latency retrieval. Reduces load on databases. Memcached and Redis are popular caches.
- Asynchronous Processing – Enqueues tasks to be handled asynchronously instead of synchronous requests. Reduces waiting and improves responsiveness.
- Stateless Systems – Stateless applications don’t retain session data so that any server can handle requests—Simplifies horizontal scaling.
- Microservices – Deconstructing monoliths into independently scalable microservices. Easier to deploy and scale individual services.
- Auto Scaling – Cloud services like AWS auto-scaling groups launch or terminate resources based on user-defined triggers like CPU usage. Provides self-regulation.
- CDN – Content delivery networks cache and distribute static assets across edge servers nearer to users. Reduces server loads.
- Queueing – Queueing mechanisms like RabbitMQ, Kafka, etc, can buffer and distribute message streams between decoupled components.
Adopting these techniques in system design allows smooth handling, increasing users and workload demands cost-effectively. A combination of strategies is recommended for well-rounded scalability. To know more about database sharding check out my article.
Key TakeAways
To conclude:
- Scalability allows a system to handle increasing workloads smoothly by adding resources like servers. It ensures optimal performance as demand grows.
- Horizontal scaling (scaling out) by adding commodity servers is more cost-efficient than vertical scaling (scaling up) with expensive hardware.
- Distributing load across components (e.g. database sharding) and decoupled microservices helps create scalable architectures.
- Automation, load balancing, and caching are vital for building scalability.
- Scalability leads to reliable systems that provide consistently good user experiences and avoid expensive re-work.
- Scalability should be considered early in design rather than bolted on later. Monitoring and testing at scale helps identify bottlenecks.
In summary, scalability is critical for smooth growth, both technically in terms of infrastructure and performance, as well as business success and customer satisfaction. Architecting for scalability using decoupling, distribution, and automation patterns creates long-term gains.
I hope You liked the post ?. For more such posts, ? subscribe to our newsletter. Do check out more concepts like availability in system design.
FAQ
What is network scalability?
Answer: Network Scalability means the ability to scale up network capacity and bandwidth to handle increased communication demands. This can be done using:
- Load balancers to distribute traffic across servers
- Increasing network bandwidth
- Scaling up routers and switches
- Caching frequently accessed data
- Compression to reduce data transmission loads
What is database scalability?
Answer: Database Scalability is the ability to scale database capacity and operations as data volumes and workload increase. Common techniques to make database scalable include:
- Database sharding, which partitions data across multiple database server
- Master-slave replication for read scaling
- Caching query results
- Indexing to optimize queries
- Scaling up database server resources
What is cloud scalability?
Answer: Cloud Scalability is the ability to quickly scale cloud-hosted resources up or down based on demand. It can be achieved by :
- Auto-scaling that launches or terminates resources based on rules
- Load balancers on standby that can be deployed instantly
- Quickly spinning up virtual machines without procuring physical hardware
- Cloud database services that handle provisioning and scaling
What is difference between Performance tuning versus hardware scalability?
Answer: The key differences between Performance tuning versus hardware scalability are:
- Performance tuning maximizes the use of current resources, and scalability adds more resources
- Performance Tuning gives linear returns up to a point; scalability provides returns proportional to resources added
- PerformanceTuning optimizes software, scalability expands hardware
In practice, a balance of both tuning and scalability is needed. Performance Tuning stretches current capacity while scalability expands infrastruct
How does caching help improve scalability?
Answer: Caching frequently accessed data in memory reduces database queries and repetitive backend work, improving throughput and response times at scale.
How can you test the scalability of your systems?
Answer: Load tests and capacity planning at projected peak usage help uncover scaling bottlenecks before launch. Monitoring in production reveals scaling needs over time.


